we need to be careful with handling the contextual data and avoid privacy issues
How to do it with machine learning?
the input are behavioral data, which are collected when user views, clicks, purchases, dwells etc.
they capture what the users do, not what they say
watches 80 % of a video = interest, positive signal
repeatedly skips a song = negative signal
those data are often noisy, they need to be preprocessed
the signals are usually positive only
they are easier to capture, if a user ignores an item, it does not mean that it was not interesting, but there could have been another more interesting item next to it
so the negative signals are ofter really noisy or ambiguous
they form “implicit feedback datasets” = full of implicit behavioral signals
opposite are “explicit feedback datasets” = reviews, ratings etc.
these datasets are presented in the form of: user-item interaction matrix
users vs. items and 1 = positive signal and 0 = missing or negative
these matrices are usually really sparse (almost empty)
data preprocessing
data cleaning:
remove bots (not real users), duplicates and corrupted data
normalize timestamps and unify item IDs
filtering users and items
drop users and items with too few interactions (not enough value there)
could be cold starts (e.g. new users, and we don’t know anything about them from previous sessions)
feature engineering
split to training and hold-out test dataset
the traditional split on training, validation and testing dataset does not work here
we will split each user’s interactions instead:
take some of their interactions for training
take the other part of their interactions for testing/evaluation
the input for training is the original matrix with the testing interactions hidden (instead of 1 is now 0)
and the model has to learn from the user’s behavior (= interactions) which are currently “visible” (the training ones)
and the models has to predict ALL (so even the held-out) interactions
in the train and test dataset, users and items are the same, but some of the interactions are hidden (held-out)
it’s like time-travelling backwards, we pretend that we don’t know about some interactions and we are trying to predict them
making predictions
they are stored in a predictions matrix (again users vs. items), but now with relevance score (the higher score, the more probability that the user would like the item) for each user-item pair
evalution
we select the top-K highest items for a particular user → a ranked list of items
evalution methods:
precision@K: out of the items in the ranked list, how many of them are relevant (now we are looking at all interactions including the hold-out ones)
high precision = many of the selected items were truly relevant
recall@K: out of all relevant items to the user, how many are truly in the ranked list (that were predicted)
high recall = we successfully retrieved items that the user really cares about
Data perspective
items can have a visual features (fun-looking, luxury-looking, interesting) and descriptive features (who made it, what is the color, where it was made etc.)
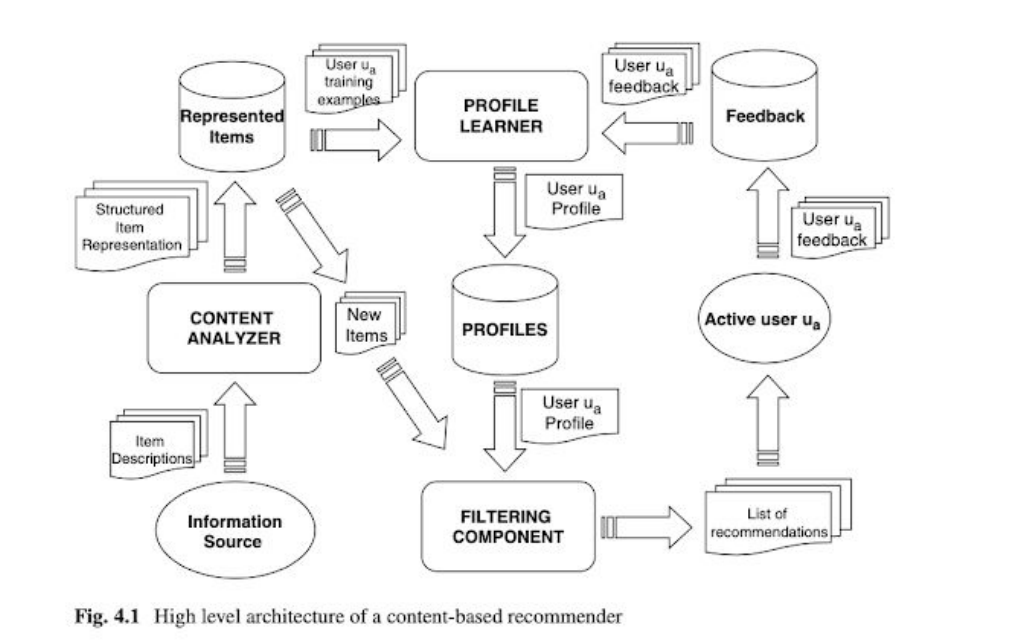
Content-based recommendation algorithm
descriptive and visual attributes of the items are used to make recommendations
the idea: if you liked certain items in the past, recommend similar items based on their content/features
first part: create item representations based on visual and descriptive features
information source → content analyzer → represented items
raw data → extract structured features from data → save in the structured database
second part: we learn a profile for each user by combining their behavioral data with the item representations
feedback represents user’s past interactions, which are combined with item descriptions and used for learning the model of what the user likes
third (final) part: we select items by filtering based on similarity to the profile
it does not have a cold start (all saved items are already described, there is no need to learn new data), can recommend immediately
users are independent on each other
disadvantages:
it’s limited by “what is known” and the recommendation quality relies on the quality of metadata
cannot recommend unexpected possibly interesting items (so they overspecialize and create filter bubbles)
e.g. recommending sci-fi films only and nothing else (if the user watched only sci-fi films)
Collaborative filtering
we make recommendations to a user by collecting preferences or taste information from many users
two types:
UserKNN - “what users are the most similar to this particular user”
ItemKNN - “what items are the most similar to his particular item”
an item X was recommended to me, because similar users (liking the similar set of items A, B, C) also liked this item X
advantages:
easy data, we don’t have to extract and store metadata about the items, just interaction matrix
collaborative filtering can recommend something unexpected
disadvantages:
it is not that transparent, so most users don’t understand, why was this particular item was recommended to them
cold-start, items and users could have insufficient amount of interactions (so the system cannot make accurate predictions)
popularity bias: it biases items, which are already popular (a lot of people interact with them)
it could be a good thing: popular clothes, cars etc.
also a bad thing: a bizarre, controversial news
Hybrid methods
in real life, baseline, context-based recommendations and collaborative filtering are combined together and training models (AI) are trained over user interaction data store + item data store to make complex recommendations