- web se dá procházet (crawling), indexovat (indexing) a vyhledávat v něm (searching)
Základní pojmy
Rozdíl search X browse
- search - hledám konkrétní věc
- browse - nehledám nic konkrétního, spíš daný prostor procházím
WWW (World Wide Web)
- graf webových stránek + další zdroje hostované na webových serverech
- komunikace přes protokol HTTP
- internetový prostor je zaměřen na prezentaci lidem (GUI) a informace se špatně čtou strojům
URL = uniform resource locator
- odkaz na zdroj (webová stránka, multimédium atd.)
- je to out-link z webové stránky
Meta search engine - vyhledávač, který agreguje výsledky z dalších vyhledávačů
Historie
- dříve se používalo full-textové vyhledávání, ještě před tím existovaly jenom seznamy stránek (o které se starali lidé manuálně) a pokud člověk neměl svoji stránku na takovém seznamu, tak byla velmi těžko dohledatelná
- velký boom způsobil Google s PageRank algoritmem
- Web 1.0
- prvních 15 let WWW, hodně statický content, osobní stránky
- Web 2.0
- od roku 2004, rychlé připojení
- sociální sítě, blogy, informační společnost, orientace na generování obsahu uživateli
- další zařízení mimo PCs
Typické části vyhledávání
- crawling - stahování obsahu (webové stránky)
- indexing - procesování obsahu do formy vhodné pro vyhledávání
- díky indexování už procházím malinkou část obsahu a ne celé univerzum ve full podobě
- searching - získávání relevantního obsahu pomocí dotazu
Tradiční vyhledávače
- full-text indexování a analýza linků
- dotazy jsou klíčová slova či full-text
- keyword query
- dotaz obsahující pouze pár klíčových slov
- full-text query
- celý full-text zparsovaný do keyword query
Multimediální vyhledávače
- content-based queries (navíc ke keyword query)
Obecné způsoby získávání informací
- dotaz (query)
- uživatel je schopný specifikovat svůj záměr
- je to jednorázový proces vyhledání
- keyword-based a content-based (uploadne soubor, nahraje z URL, nakreslí sketch)
- browsing
- uživatel není (dobře) schopen specifikovat svůj záměr
- skákání přes explicitní linky nebo přes “doporučené” linky - např. s podobným obsahem
- filtering
- filtrování obsahu pro mě (personalizace, podle mého chování a mé zpětné vazby…)
- je to pokračující proces vyhledávání
Je potřeba umět získávat samotné informace z textu (textové dokumenty, stránky apod.)
Získávání informací z dokumentů a stránek
Přidání hodnocení stránek nejenom podle textového obsahu
Pro vyřešení toho problému se začaly analyzovat linky (in-links a out-links) - to jsou velmi zásadní a sémanticky dobré informace. Celková váha stránky už nebyla závislá pouze na obsahu, ale také, jak je navázaná na ostatní stránky, jak se chová a spoustu dalších faktorů.
Hub - stránka se spousty outlinků
Authority - stránka se spousty inlinků
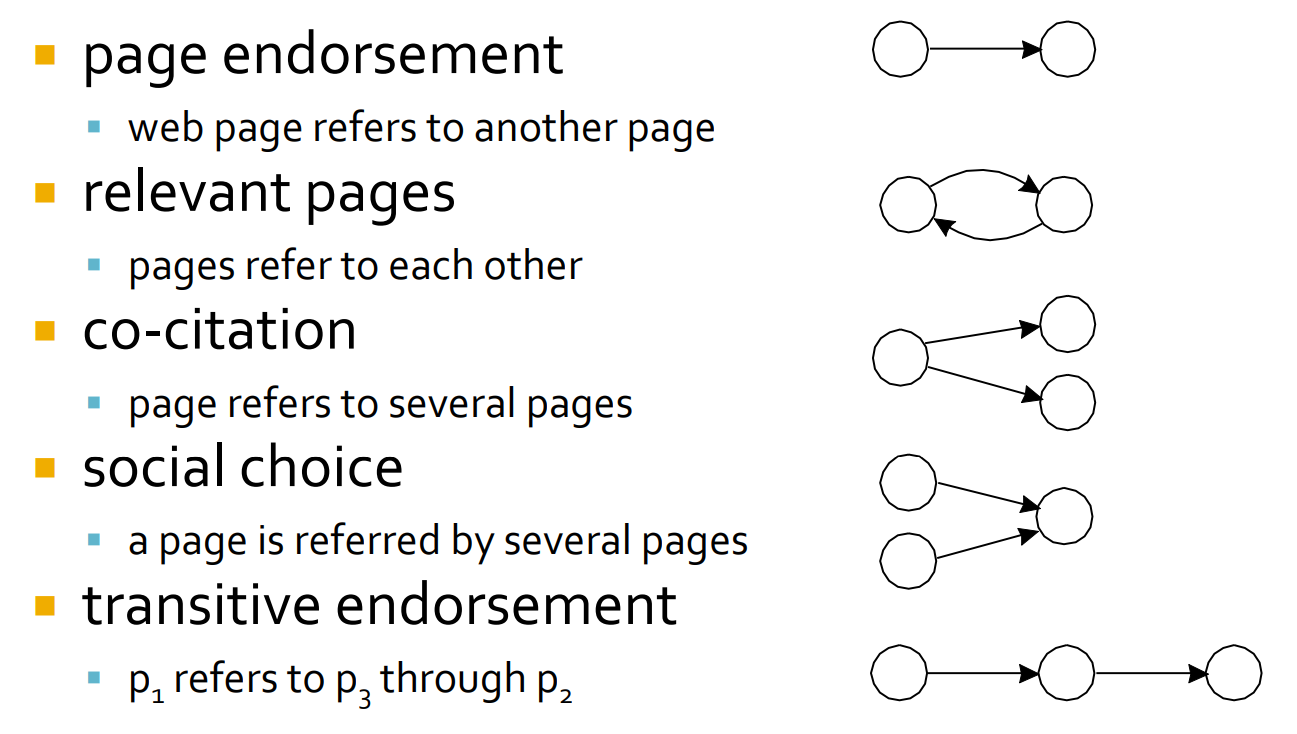
Díky analýze linků můžeme relativně snadno najít a zmapovat celé komunity na webu. Existuje několik typických schémat propojení v rámci takových komunit.
Popularita stránky se tedy měří hlavně podle počtu inlinků. Algoritmus Page Rank a HITS.
Search engine ranking a SEO
- pro lepší výsledky stránek ve vyhledávačích
Sémantický web
- aby i stroje pochopily o co na tom webu jde
Když už nějaký uživatel na naši stránku přijde, tak ho chceme udržet co nejdéle a ideálně ho proměnit v peníze :) ⇒ Doporučování a sociální kontext na webu
Získávání informací z multimédií
Aproximované podobnostní hledání
- trochu snížím přesnost za o dost rychlejší vyhledávání
Range query - pokud uživatel zná sémantiku modelu kNN query - pokud uživatel nezná sémantiku modelu (většina případů)
Early fusion - jeden deskriptor per objekt, všechny modely jsou agregovány v jednom podobnostním modelu
- multi-metric model Late fusion - každý model je reprezentován (dotazován a indexován) individuálně
- skyline operator - dotazy obsahující více příkladů
Permutační indexy
- mám pivoty a pivotovou tabulku (tabulka vzdáleností)
- místo takové tabulky vytvořím pro každou databází permutaci pivotů jednotlivých objektů reprezentovanou seřazenou množinou pivotů
- nejsou tam uložené žádné vzdálenosti, jenom pořadí pivotů
- taková tabulka je menší co se týče zabraného místa
- používají se jiné algoritmy, které s tímto umí pracovat - rychlost je vesměs stejná
FastMap
- je to metoda pro rychlé mapování vysoko-dimenzionálních prostorů (obecných metrických dat) do euklidovského prostoru. Umí si poradit i s množinami, které nesplňují běžná pravidla geometrie