Architektura aplikace má 2 významy:
- logická
- zahrnuje organizaci softwarových tříd do balíčků a jmenných prostorů (aby si stejné názvy nepřekážely + přehlednost)
- uspořádání balíčků do vrstev (prezentační, business, datová…) a podsystémů
- aby došlo k rozdělení zodpovědností (separation of concerns)
- Rozdělení architektur aplikací podle vrstev
- MVC a MVP architektura
- fyzická
- fyzické rozdělení systému na komponenty
- rozložení systému na více výpočetních uzlů
- thin client / smart server
- thick client / dumb-server
- enterprise service bus
- microservices
Samotné programování a vývoj aplikace je menší část nákladů → návrh architektury je velmi zásadní, pokud je dobrý, pak už se to programuje samo ;)
Chci zajistit hlavně:
- srozumitelnost - rychlá lokalizace chyb, moji práci může rychle převzít někdo jiný, rychlejší spolupráce v týmu
- rozšiřitelnost - změny nesmí ovlivnit nesouvisející část systému
- udržitelnost aplikace
Hlavní pozornost věnuju místům, kde bude systém v budoucnu rozšiřován - tato místa je potřeba od zbytku aplikace oddělit nějakým zapouzdřením/rozhraním (Rozhraní (Interface)), aby byla snadno rozšiřitelná a zároveň rozšíření neovlivnilo zbytek aplikace.
Diagram balíčků
- definuji jím jak na sobě různé balíčky tříd souvisejí a závisí
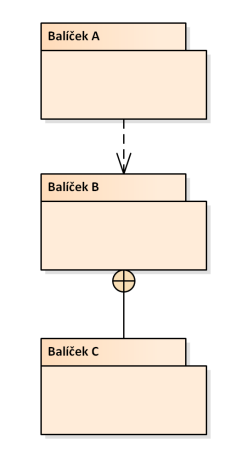
- zde ta horní relace je: A je závislý na B
- dolní relace je: C je uvnitř B (vnoření)
- obecně se chci snažit nemít cykly v diagramu balíčků
- pokud se tak stane, tak můžu 1) přesunout problémovou třídu, 2) vyčlenit třídy do nového balíčku a 3) vytvořit rozhraní (dependency inversion)
Návrhový model tříd
-
dokumentuje provedená architektonická rozhodnutí
-
zachycuje různé zodpovědnosti různých tříd
-
dokumentuje použité vzory a principy
-
pokud je napsaný dobře, tak je možné z něho rovnou generovat zdrojový kód
-
může vycházet z doménového modelu, jen se zpřesní atributy a metody (přidají se např. datové typy, výstupní typy metod, viditelnosti) a upřesní se relace (jejich směr, názvy konců asociací) a vytvoří se nové softwarové třídy (tedy ty, které nezastupují žádnou reálnou věc, ale jsou potřeba pro správný objektový návrh)
-
doporučení (hlavně pro přehlednost a přínos)
- nezobrazovat gettery/settery
- není potřeba zachycovat všechny softwarové třídy
- důležité je popsat principy a pravidla, která mají být během implementace dodržována
-
vysvětlení značení:

Rozdělení architektur aplikací
- monolitická architektura
- dvouvrstvá
- třívrstvá
- vícevrstvá
Monolitická architektura
- pro aplikace, které nemají ambici být dlouho v provozu (např. mají jeden účel a po splnění končí)
- všechny vrstvy (prezentační, aplikační, datová) jsou na jednom stroji
- pro prototypy, mají rychlý počáteční vývoj, ale velmi špatně se udržují, rozšiřují a škálují (je nutné je mít jako celek)
- velmi dobře se testují
Dvouvrstvá aplikace
- naprostý základ, dělení na prezentační a datovou (= zbytek aplikace) vrstvu
- CRUD aplikace
- thin-client / smart-server
- tradiční aplikace
- logika je na serveru
- thick-client / dumb-server
- moderní přístup
- server = API (většinou jenom datová vrstva)
- aplikace běží na straně klienta
- větší zátěž na stroj klienta, nutnost reinstalace u klientů při aktualizaci
- záleží, jestli je většina logiky na straně klienta nebo serveru
- trend je v cyklech - co se používá teďko (teďko se to vrací z logiky na FE zpátky na BE)
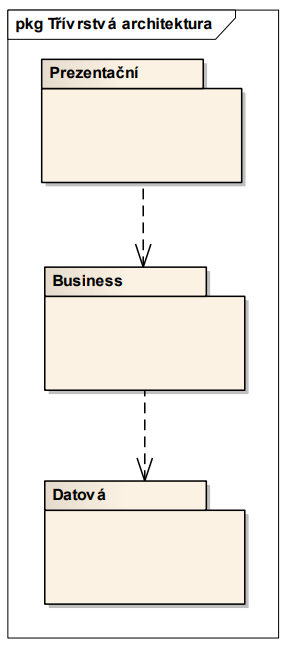
Třívrstvá aplikace
- větší (enterprise) aplikace
- vrstvy (každá může být na odděleném serveru):
- prezentační - HTML stránky, zpracování požadavků od uživatele, routování, formátování, GUI, API
- business (aplikační) - logika, procesy a validace, měla by být nezávislá na prezentační a datové vrstvě
- datová - persistence dat
- přidává se i tzv. “middleware” vrstva, která zajišťuje efektivní, standardizovanou a škálovatelnou komunikaci mezi jednotlivými vrstvami (to může být například Enterprise service bus)
- striktní - závislost mezi vrstvami jde vždy směrem dolů a pouze o 1 úroveň
- relaxovaná - závislost je také směrem dolů, ale přes lib. počet úrovní
- nejvíce používaná
- nenutí mě všechno rvát přes business (když chci zobrazit raw data z databáze, tak si pro ně mohu sáhnout hned)
- ve striktní bych musel používat wrappery v business třídě (což je někdy zbytečnost navíc)
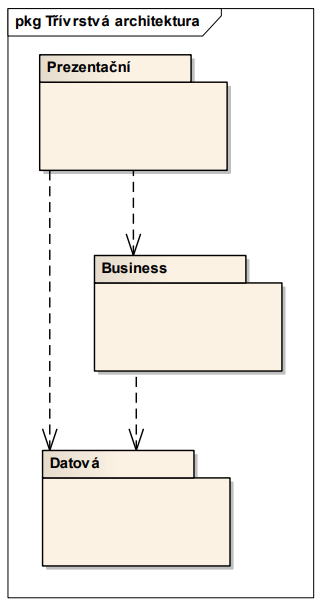
- ve striktní bych musel používat wrappery v business třídě (což je někdy zbytečnost navíc)
- výhody třívrstvé architektury:
- oddělení business logiky od prezentační (narozdíl od dvouvrstvé)
- snadná výměna vrstev
- jednoduché testování
- možnost mít více prezentačních vrstev
- znovupoužitelnost (logování, emaily, persistence apod.)
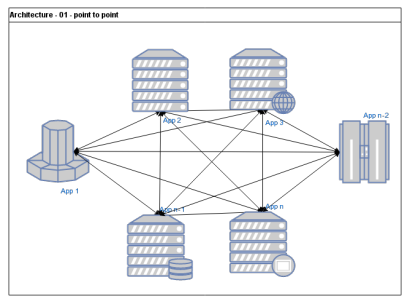
Point-to-point architektura
- špagetové propojení
- mash-up aplikace, jsou těžko udržitelné
Enterprise service bus
- centrální moderátor, který zajišťuje
- vyhledávání služeb
- zasílání zpráv mezi službami (services)
- dynamické routování pro zprávy
- message enrichment - může jednotlivé zprávy obohacovat o další context od ostatních aplikací zapojených v ESB
- je možné komunikovat pomocí více různých protokolů (SOAP, HTTP protokol, FTP, JMS atd.)
- load balancing
- kontroly stavů jednotlivých aplikací
- může dělat session pooling
- tj. držet pool otevřených připojení k nějaké aplikaci (u které je vytvoření připojení drahé - např. databáze) a podle potřeby je přiřazovat jednotlivým klientům
- jedno spojení tedy může být využito více různými services/klienty
- dynamické routování požadavků na základě obsahu jednotlivých messages
- mediace Mediator
- zachování připojení k legacy aplikacím
- zabezpečení
- dá se rychle škálovat nasazením další aplikace a připojení do Enterprise service busu
- má různé adaptéry pro různé komunikační protokoly a aplikace
- nemá v sobě business logiku, je většinou stateless, slouží pro interní účely
- nemusím znát jména a konkrétní adresy aplikací - prostě pošlu požadavek a ona ho “nějaká” aplikace obslouží
- všechny tyto funkcionality pro ESB zajišťují jeho “interní” middleware services
- aby bylo dobře zajištěná komunikace mezi různými systémy, často je potřeba definovat (a uložit) mapování mezi jednotlivými entitami
- např. máme požadavek od zákazníka (a u něj máme uložené jednotlivé přiřazené ID k informacím v CRM systému, pak ID k informacím v OMS systému atd.)
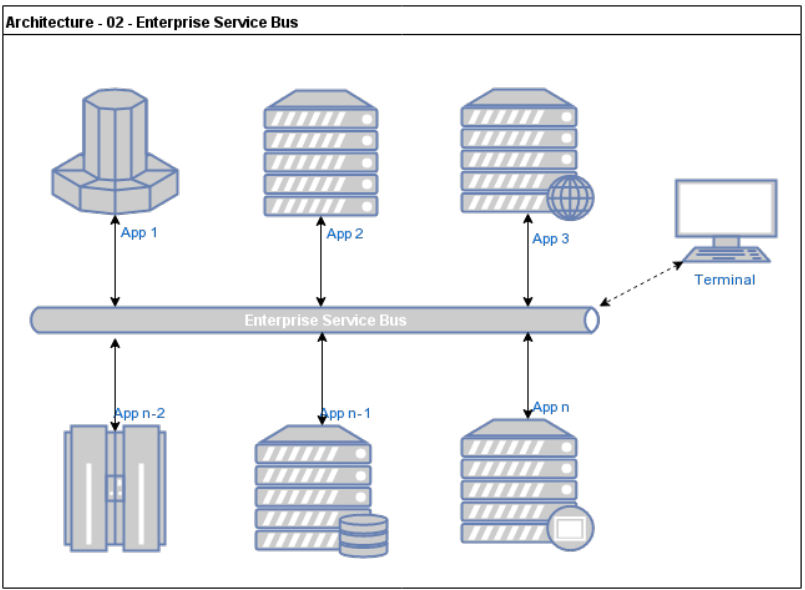
- např. máme požadavek od zákazníka (a u něj máme uložené jednotlivé přiřazené ID k informacím v CRM systému, pak ID k informacím v OMS systému atd.)
Microservices
- https://microservices.io/
- malé služby, které mají jen jeden účel - umí fungovat samostatně a izolovaně
- může každá běžet na vlastním serveru
- spojuji je do sebe (pomocí Rozhraní (Interface)) a můžu pro to vytvořit FE
- jsou loosely integrated (jejich funkcionality se nepřekrývají a nejsou tzv. “hard-wired”)
- dekompozice služeb
- výborná škálovatelnost
- dá se jednoduše horizontálně škálovat
- jedna funkcionalita = 1 služba
- dobrý na to je např. Python
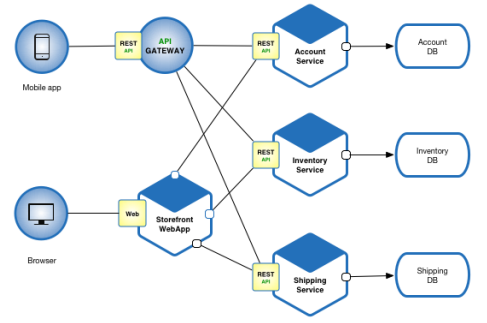
Hexagonální architektura
- na levé straně je komunikace s vnějším světem (REST, SOAP, GraphQL atd.)
- z pravé straně jsou interní systémy (databáze, repozitáře atd.)
- funguje na principu několika malých hexagonů, které jsou do sebe propojené
- je to způsob používání Microservices
- dá se říct, že je to propojení několika menších monolitů
- v principu je hexagonální architektura monolit
- pak je tam ta škálovatelnost náročnější, ale můžu mít více takových monolitů vedle sebe a nějaký může být fakt jako microservice, kterou mohu rozšiřovat
- a tyhle monolity pak můžu kombinovat k sobě
- v principu je hexagonální architektura monolit
- v hexagonu můžu mít více malých hexagonů