Obecně, jak funguje databáze: Jak funguje databázový systém
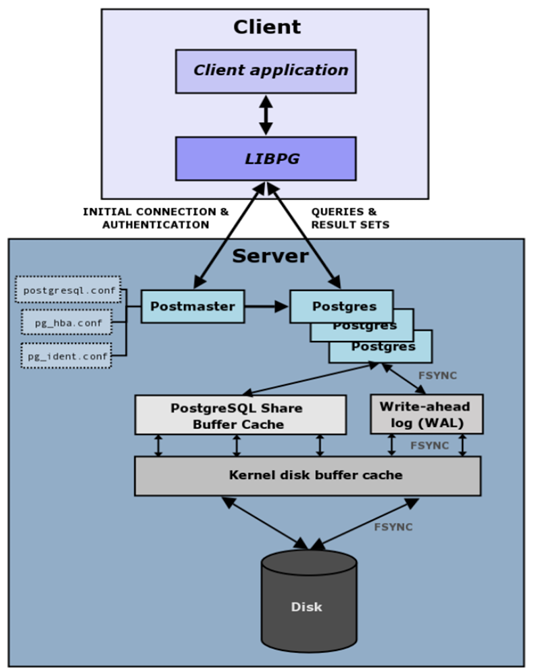 LIBPG - knihovna, která implementuje komunikaci s PG serverem
Postmaster - hlavní proces PostgreSQL, funguje taky jako listener
LIBPG - knihovna, která implementuje komunikaci s PG serverem
Postmaster - hlavní proces PostgreSQL, funguje taky jako listener
- spravuje ostatní procesy, připojení a inicializaci serveru
- pokud se povede auth, tak vypooluje nový Postgres proces, který se pak s klientem baví Téhle architektuře se říká Dedicated (nebo process-per-connection)
- pro jednoho klienta mám dedikovaný proces, který se o něj celou dobu stará
- proces zanikne, jakmile zanikne TCP/IP spojení
postgresql.conf- konfigurace při startu (bere ji Postmaster proces)
Postgres proces
- od klienta přijímá a vykonává SQL příkazy
- používá 2 sdílený paměti
- shared buffer cache - velký blok cache paměti, kam se tahají data, když se s nimi pracuje
- drží většinu často používaných tabulek
- nemělo by to být více než 1/3 RAMky počítače/serveru
- WAL - write ahead logy = journal
- zajištuje ACID (Atomicity a Durability hlavně)
- fsync je systémová funkce, která zajistí, že se ty změny zapíšou z cache na disk (periodicky) (nezůstanou jenom v cache - kdyby to náhodou kleklo, tak je ztratíme)
- shared buffer cache - velký blok cache paměti, kam se tahají data, když se s nimi pracuje
Rozložení dat a tabulek
- jeden cluster může obsahovat více databází (viz Jak funguje databázový systém)
- vytvoření DB má málo režie, v jednom clusteru můžu klidně mít více DBs pro více aplikací
- každý cluster může mít jinou verzi Postgresu
- každý cluster pak má svoje konfigurační soubory a musíme je spravovat zvlášť
- má default tabulku:
postgres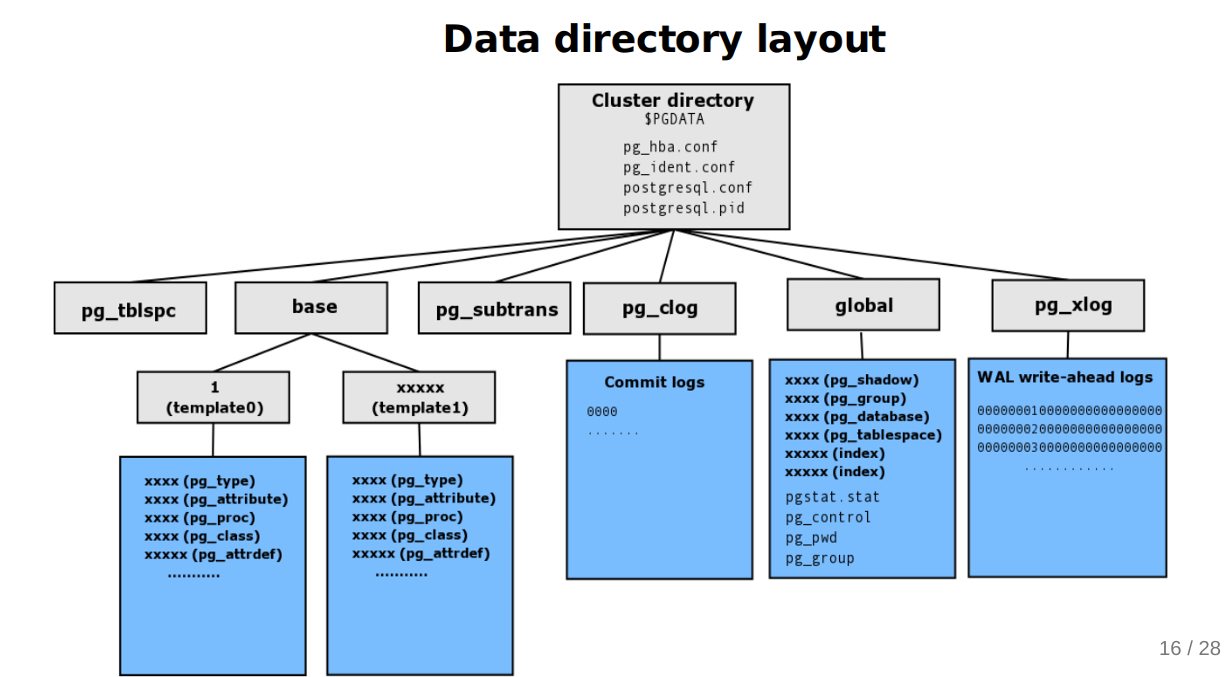
- vnitřní implementace dat
base/(ukládá data jednotlivých databází, vč. tabulek a indexů)- 1 podadresář = 1 databáze
- 1 soubor = 1 tabulka (jsou to nějaký binární soubory)
- 1 podadresář = 1 databáze
global/- globální data sdílená mezi databázemi (např. informace o uživatelích a rolích)