the entropy of each child is weighted by the proportion of entropy of instances belonging to the child
the split does not have to be of equal lenghts (one child can get more instances, therefore its information gain has to be scaled proportionally)
by splitting, we want to maximize the information gain
GINI impurity
alternative to entropy
it is computationally cheaper
best split minimizes the weighted average GINI impurity
between 0 and 0.5
GINI(node)=1−∑i=1Npi2
GINI(split)=p(c1)∗GINI(c1)+p(c2)∗GINI(c2)
the goal is to minimize this weighted split GINI impurity
Stopping rule
determines, when to stop the recursive splitting the tree in the subgroups
more rules apply:
maximum depth reached
prevention from overfitting (and better interpretability)
minimum samples per node
so the reliable assignment can be made (and it also reduces overfitting)
minimum impurity decrease
any next split won’t pass the defined purity decrease
also helps with the overfitting
smaller tree = not likely to be overfitted, faster to train, more interpretable
Assignment rule
determines, which label value is assigned to defined leaf node
common assignment is to assign the most frequent class present in the node
but not in all cases!
Logistic regression
Parametric learning
trying to predict the label as the mathematical function of the other features (with weights)
we have linear, polynomial, linear with feature interactions or neural networks
model learning is how much each feature contributes to the target label
through minimizing the loss function, which measures the error of the predicted values (compared to real target label values)
e.g. MSE (mean squared error is used) - see Evaluace
gradient descent - algorithm for iterative updating the feature weights (=parameters) to minimize the loss function
it uses the gradient (= first derivative of the loss function) with respect to the parameters
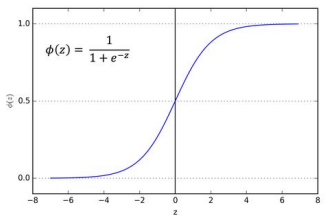
Logistic function
also known as the sigmoid function - it maps all real numbers to the range [0,1]
decision boundary is z=0
near z=0, small changes near the decision boundary result in big changes in the probability
Logistic regression
classification algorithm that models the probability of the binary outcome using the Logistic function applied to a linear combination of features (with weights)
process:
we calculate a weighted sum of features (just like linear regression)
the result z can be in [-inf, inf]
apply the sigmoid function (the logistic function)
σ(z) = 1 / (1 + e^(-z))
this gives us a P(y=1|x), a probability that the target label is 1 given features x
if it is more than 0.5, predict 1, othewise predict 0
output is a probability between 0 and 1 (e.g. there is a 45 % probability that this client will churn this month)
this is often a baseline classification model and is very interpretable (we instantly know, how much each feature affects the result)
to transform the probability of the binary result, we apply a decision threshold (it is often 0.5, but now always)
Binary Cross-Entropy
= a loss function used to learn a logistic regression model
it measures how far the predicted probabilities are from the actual labels
BCE=−[yᐧlog(y^)+(1−y)ᐧlog(1−y^)]
it has two parts and only one is “activated” based on whether we are testing how far is the prediction from y=0 or y=1
it penalizes being confidently wrong
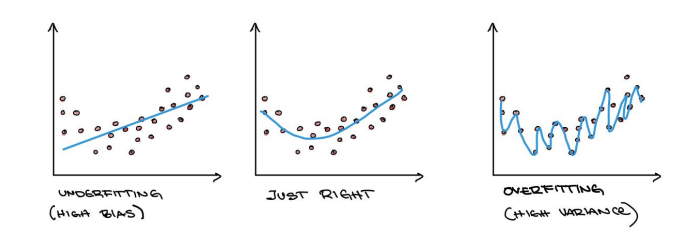
How to spot overfitting?
as high accuracy/low error on the training set and low accuracy/high error on unseen data
the model has learned a lot of signal (= data useful for generalization) and also a lot of noise (= data that does not lead to generalization)
How to spot underfitting?
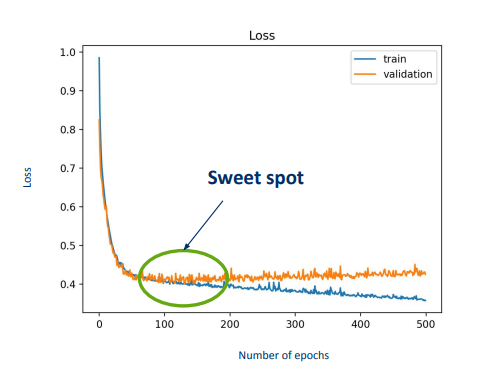
on a learning curve:
the training and validation loss are both decreasing (we need more epochs for it to decrease more and see where is the sweet spot (where the loss is minimized))
or when the training and validation curve is not decreasing (or just really slowly) ⇒ our model is too simple for the data
Bias-variance trade-off
trade off between underfitting and overfitting
sweet spot on the learning curve:
when both the training and validation loss is decreasing together
and stop at the point, when by more epochs we don’t gain any more loss decrease from the validation “unseen” data
Early stopping
a technique that prevents both underfitting and overfitting by “watching” the loss on the validation data
when the loss on validation data stops decreasing or even start increasing, the technique stops the training and returns the best model (= best weights) found
Regularization
techniques that penalize the complexity of the model (which prevents overfitting)
it prevents the model from learning from the noise in the data (from using too complex patterns)
L1-regularization (Lasso)
adds a sum of current absolute weights multiplied by some λ parameter as a penalty
L2-regularization (Ridge)
the same, but instead of absolute weights, use squared weights