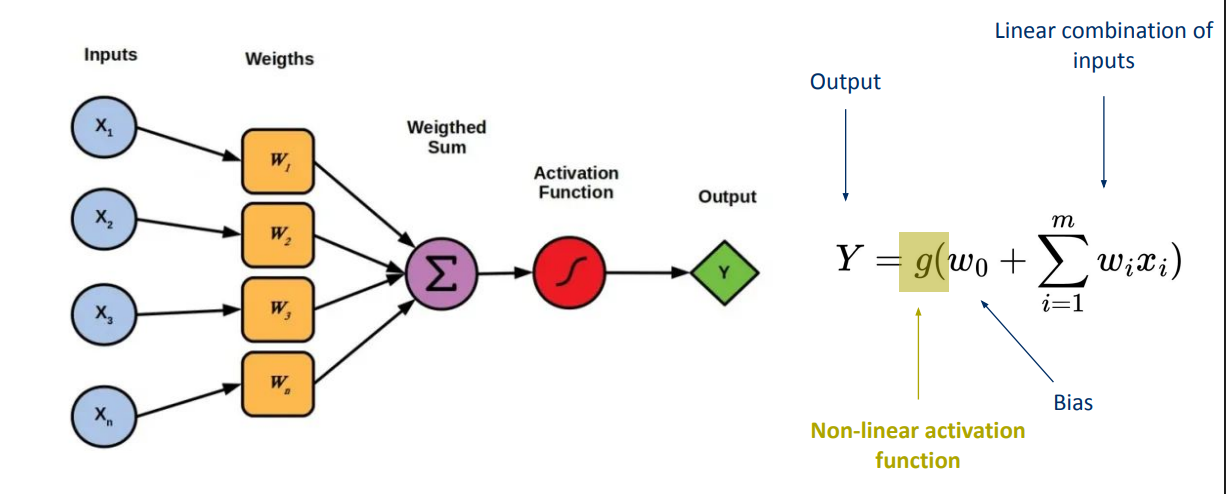
it’s called an activation function, because it activates at some threshold
if the input (the linear combination of inputs shifted by the w0 bias) exceeds some threshold, the activation function “fires”, similarly to a neuron in the brain
examples:
ReLU (Rectified Linear Unit) - fires, when the argument is greater than 0
most used today
Sigmoid (Logistic function) - for logistic regression
and the loss function is differentiated to get gradients which tell us in which directions to update the weights and biases in backpropagation
Backpropagation (backwards pass)
the goal is to minimize the loss function by propagating the errors back to update the individual weights
How does the model learn?
using gradient descent algorithm:
initialize weights randomly
in a training loop:
complete a forward pass (compute predictions on all training instances)
complete a backward pass (compute gradients (calculate loss function and differentiate) + update weights)
one loop is called one epoch
repeat until a stopping criterion is met
a maximum number of epochs
loss stops decreasing meaningfully
loss on validation data goes up (a sign of overfitting)
using stochastic gradient descent
forward pass is performed only on a subset of training instances (also called a batch)
Advantages of neural networks
capable of generalizing very well
are a good universal approximators, they can approximate any continuous function up to given error E (but sometimes it requires an insane amount of neurons)
the Universal Approximation Theorem: A sufficiently large neural network with just a single hidden layer can approximate any continuous function on a compact subset of to arbitrary accuracy.
conditions: we need a non-constant, bounded and monotically increasing activation function + we need “enough” neurons in the hidden layer
the approximation is theoretically possible, but it does not guarantee, that we will find the right parameters by training (the optimization may fail)
Disadvantages of neural networks
are black-box techniques, no good interpretation of the model
prone to overfitting (memorizing instead of generalizing)
gradient descent can get stuck in local minima
Deep learning
extract patterns from data using neural networks
machine learning uses deep learning techniques to be able to learn without being explicitly programmed, machines can improve at tasks with experience
artificial intelligence includes machine learning, which includes deep learning
Convolutional Neural Networks (CNNs)
used in image processing applications (or any other data represetable in grid-like 2D matrix or a tensor)
two main operations:
convolution
moving a small kernel (= a filter) over the matrix and computing a dot product at each position
each filter learns to detect a specific pattern (edge, corner, texture etc.)
pooling
reduce the dimensions of the data by taking the average or max of a window/tile
there are many CNNs pre-trained from scratch
famous MNIST dataset with handwritten numbers for a CNN to learn
Recurrent Neural Networks (RNNs)
used in text and speech processing applications (or any other data treated as a sequence)
they are based on memory and they also have feedback loops (going backwards unlike in the feed-forward neural networks)
they maintain a hidden state (the “memory”) which accumulates information from previous inputs (so it keeps the context, which is important for speech, audio, video…)
the output from the previous state is the input to the next state
architectures:
LSTM (Long Short-Term Memory)
LSTM modules have gates
forget gate - decides which parts of the long-term memory could be forgotten
input gate - decides which new information should be stored in the long-term memory
output gate - decides which information should be passed to the next LSTM module (short memory)
GRU (Gated Recurrent Unit)
simplification of the LSTM with only two gates
update gate - what to forget and what new information to add to memory
reset gate - how much of the past to use and what to ignore when receiving new information
today, these are being replaced by Transformers
Autoencoders
used for unsupervised learning tasks (image denoising and data compression)
it’s trained to reconstruct its input
two parts:
encoder - compresses the input into a low-dimensional latent represenation
(bottleneck in between)
decoder - reconstructs the original input
the bottleneck forces the network to learn only the most important features, it cannot memorize everything, it must discover efficient representations
Transformers
introduced by Google in 2017 in the paper “Attention is all you need” and then took the ML world by storm