- je open-source, původně od Facebooku, nyní vyvíjí Apache Software Foundation, implementována v Javě
Architektura
- používá se masterless ring architektura (peer-to-peer) - tedy neexistuje žádný hlavní uzel, všechny uzly jsou si rovnocenné (narozdíl od master-slave přístupu, kde odolnost stojí a padá na master uzlu)
- tato architektura je velmi odolná vůči výpadku uzlu (žádný SPoF = single point of failure)
- data se rozprostřují po celém kruhu
- a dál se jednotlivé kruhy mohou nacházet na fyzicky oddělených datacentrech nebo v cloudu
- kolikrát jsou replikované = to mi říká replikační faktor
- jednoduše se spravuje a škáluje
Komunikace mezi uzly
- pomocí protokolu Gossip - pomocí něho mezi sebou uzly komunikují
- jmenuje se gossip, protože kromě informací o sobě předávají informace o ostatních známých uzlech
- předává informace o stavu clusteru, jednotlivých uzlů a umístění dat
- Seed uzly - slouží pro inicializaci uzlů v clusteru
- nový uzel získá první informace o topologii a dalších uzlech právě ze seed uzlu a pak už může normálně komunikovat (pomocí Gossip protokolu)
- v clusteru je více seed uzlů pro zajištění dostupnosti a stability
- heartbeat signály - posílají se pravidelně a informují o “životě” uzlu
- Phi Accrual Failure Detector - varianta failure detektoru
- monitoruje dostupnost uzlů, sleduje intervaly mezi heartbeat signály
- hodnota phi udává pravděpodobnost, že je uzel mrtvý
Replikace
- replikují se na základě replikačního faktoru
- typ replikace se určuje při vytváření Keyspace
- existuje komponenta “Partitioner”, která daná data rozděluje podle dané replikační strategie
- 2 replikační strategie:
- SimpleStrategy - spíš jenom na testovací účely - pro data v 1 datovém centru
- určí se uzel pro první repliku a pak se replikuje na další uzly po směru
- NetworkTopologyStrategy - jde nastavit různé replikační faktory pro různá datová centra
- určí se první uzel replikace a pak nejbližší po směru v jiném racku
- SimpleStrategy - spíš jenom na testovací účely - pro data v 1 datovém centru
- data se verzují pomocí časových razítek
Odolnost
- existují samoopravné mechanismy
- data z nedostupných uzlů se automaticky redistribuují
- pokud se zjistí, že je nějaký uzel nedostupný (pomocí Phi Accrual Failure Detectoru) a Gossip protokolu → tak se data rozdistribuují na další uzly, aby se splnila replikační strategie a počet replikací
Škálovatelnost
- založeno na horizontálním škálování - hashovacími funkcemi se rozdělují data v clusteru
- uzly jsou organizovány do kruhů (masterless ring architektura) a každý uzel je zodpovědný za určitý hashovací rozsah
- tedy stačí přidat další uzel do clusteru místo nakupování výkonnějšího HW pro existující uzly
- a Apache Cassandra automaticky začne rozdělovat data i na tento uzel (tedy všechny uzly budou zodpovědné za menší rozsah dat)
Databázový model
- máme základní struktury:
- Keyspace (= databáze v relačních)
- nejširší objekt v databázi - definuje chování dat (replikační faktor, replikační strategie, typ zápisu dat)
- udržuje pohromadě všechny Column Families
- každý keyspace může mít jiný replikační faktor
- Column family (tabulka v relačních)
- definuje strukturu dat
- pokud chci nějaká data číst společně, je vhodné na to vytvořit column family
- počet sloupců je libovolný pro každý řádek, ale primary key musí být vždy přítomný
- Row - nemá pevnou strukturu, každý řádek může obsahovat jiný počet sloupců
- je to kolekce sloupců
- každý řádek má unikátní row key
- Column
- a pair of column name + column value (+ possible additional metadata)
- metadata: TTL (pro dočasná data), timestamp (last modified)
- může mít hodnoty:
- null, atomické hodnoty (text, čísla, datum, tuples, UDT (user-defined type))
- kolekce (lists, sets and maps)
- a pair of column name + column value (+ possible additional metadata)
- Super Column = tabulka v tabulce
- objekt rozšiřujeme o další vnořený objekt (časté využití)
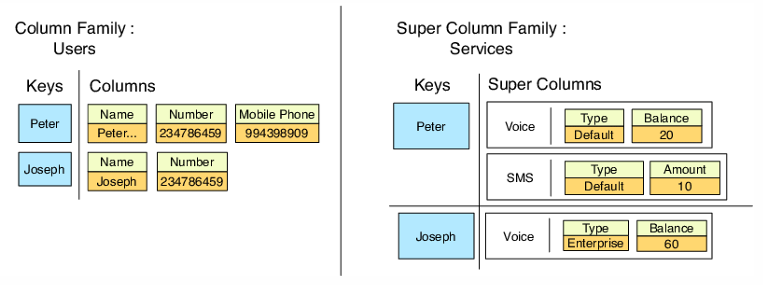
- objekt rozšiřujeme o další vnořený objekt (časté využití)
- Keyspace (= databáze v relačních)
- primární klíč
- složený z partition klíče a jednoho či více clustering klíčů
- partition - definuje, na jakém uzlu/shardu se data uloží (na základě hashové hodnoty)
- clustering - určuje pořadí dat na daném uzlu, podle něj se implicitně sortí
- složený z partition klíče a jednoho či více clustering klíčů
- zajímavé datové typy:
- varint - integer s libovolnou přesností
- counter - 8B signed integer
- podporuje pouze operace inkrement/dekrement, nemůže být součástí primárního klíče, TTL není podporováno a buď jsou všechny sloupce v tabulce countery nebo žádný z nich (to plyne z interní implementace)
- také se jedné o CRDT (podobně jako v RiakKV)
- sets and maps
- are internally sorted
CQL - Cassandra Query Language
- je to SQLko bez joinů (je také deklarativní)
- je možné definovat svoje uživatelské datové typy (UDTs)
- lze používat v CQLSH, což je interaktivní command line shell pro práci s Apache Cassandra
Selekce
- WHERE má poměrně striktní pravidla (která plynou z architektury a distribuované povahy databáze)
- podmínky mohu klást jenom na partition keys (pokud nepovolím ALLOW FILTERING)
- pokud použiji cluster columns, musím je použít v tom pořadí, ve kterém jsou definované (a nesmím nějaké přeskočit)
- pokud chci podmínky i na non-key sloupcích, musím používat sekundární indexy nebo ALLOW FILTERING
- v Apache Cassandra se struktura databáze designuje na budoucí strukturu dotazů (tj. je to trochu opačně než u např. relačních databází) - každá tabulka se pak optimalizuje tak, aby co nejvíce vyhovovala (nejčastějším) dotazům
- ORDER BY - pouze podle clustering keys/columns
- GROUP BY - pouze podle partition key columns
- ALLOW FILTERING
- provede se sken jednotlivých partitions a vyhledá se hledaná hodnota
- toto může být velmi neefektivní na velkých tabulkách, proto se to v produkci příliš nepoužívá
Insert
- vždy musí být vloženy alespoň hodnoty partition key sloupce/sloupců a (pokud je mám definované) cluster key values (protože dohromady pak formují kompletní primary key)
- Cassandra nikdy automaticky negeneruje primary keys
Update
- pokud aktualizovaný záznam v tabulce není, je vložen
Delete
- může smazat celý řádek, pouze nějaké sloupce, elementy kolekcí a nebo pole v UDTs
Distribuce dat
- data se dělí pomocí Partition key (rozděluje se na základě hashování, aby byla data konzistentně rozdělená mezi uzly)
- replikační faktor 3 = data budou uložena na 3 uzlech
- lze nastavovat úroveň konzistence (kolik uzlů musí odpovědět na požadavek):
- ONE: data jsou čtena/zapsána na jeden uzel
- QUORUM: nadpoloviční většina replik musí odpovědět
- ALL: všechny repliky musí odpovědět
- kvůli distribuci dat Cassandra nativně nepodporuje operace, které vyžadují iteraci přes všechny hodnoty v jednom sloupci - jednotlivé části dat jsou po různých částech systému (díky partition keys), takže proiterovat je všechny by bylo velmi výpočetně náročné
- lepší jsou agregační funkce, které jsou dobře zacílené (na jeden partition)
- a já tedy (stejně jako designuju celou databázi podle toho, jaké chci mít hlavní dotazy), tak designuju i partition key tak, aby data, která chci mít ve shardu společně byly ve shardu společně (používá se konzistentní hashování, takže to jde)
CAP teorém
Základní nastavení (AP):
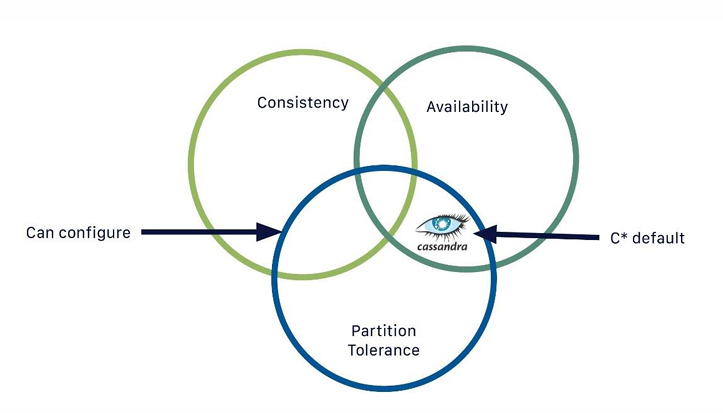
- není splněna konzistence - data se nakonec zapíšou, ale neexistuje garance, kdy se tak stane Je možné překonfigurovat do CP