Hadoop je open-source framework pro “distribuované, rychlé, levné, bezpečné ukládání a zpracovávání velkých objemů dat jakéhokoliv typu”
- jde zpracovávat strukturovaná i nestrukturovaná data
- běží na běžném “commodity” HW, čímž snižuje náklady (místo výkonného serveru spíš více méně výkonných)
- automatické replikace zajišťují dostupnost dat při výpadku
- implementován v Javě
Komponenty/moduly
Hadoop Common
- společné funkce a podpora pro další moduly
HDFS
- = Hadoop Distributed File System
- je to distribuovaný hierarchický souborový systém pro ukládání dat v clusterech
- založený na architektuře master-slave
- NameNode (master): metadata o uložených souborech + koordinuje přístup k souborům a operace čtení a zápisu
- je to SPoF - bez něj je cluster nepoužitelný, řeší se to tzv. SecondaryNode (ale ten není všude)
- poskytuje rozhraní pro všechny operace s HDFS (uživatel nemůže komunikovat přímo s DataNodes)
- DataNode - ukládají samotná data a posílají “heartbeat” zprávy NameNodu
- NameNode “zařídí” požadovanou operaci (zjistí, jaký DataNode, jaká jsou oprávnění apod.), ale samotná data proudí od uživatele přímo ke konkrétnímu Data Node (NameNode není bottleneck)
- NameNode (master): metadata o uložených souborech + koordinuje přístup k souborům a operace čtení a zápisu
- princip používání
- každý soubor se rozdělí na bloky (o stejné velikosti), které se uloží na různé DataNodes
- každý soubor má pak i svoje definované group permissions
- rozdělení a správu řeší NameNode
- data se ještě replikují, aby byla zvýšena odolnost vůči chybám a zvýšila se read performance (to zajištuje sám DataNode)
- replikační faktor je většinou 3
- strategie volení replik - bere se v potaz fyzické umístění replik
- rack-aware strategy - propustnost sítě mezi replikami ve stejném racku je větší než když jsou oba v jiném racku/jiném datacentru
- většinou jsou dvě repliky ve stejném racku a jedna v jiném racku
- každý soubor se rozdělí na bloky (o stejné velikosti), které se uloží na různé DataNodes
- celý cluster je jeden velký namespace
- výhody
- škálovatelnost, odolnost vůči chybám, jednoduché ukládání velkých souborů
- nevýhody
- nemá nízkou latenci a je pomalý při častých aktualizacích dat (preferuje přístup write once, read many)
Hadoop MapReduce
- konkrétní implementace programovacího modelu MapReduce
- master je “JobTracker”, slave je “TaskTracker”
- input data se berou ve spolupráci s NameNode v HDFS
- je to jedna z aplikací, která může běžet na YARN
- hlavně transformuje a analyzuje data uložených na HDFS
- “specifický výpočetní model pro dávkové zpracování dat”
Hadoop YARN
- = Hadoop Yet Another Resource Negotiator
- je to resource manager v Hadoopu a job scheduler
- odděluje správu zdrojů (paměť, CPU, disk…) od výpočetních frameworků (jako je MapReduce a Spark)
- takže můžu efektivně a flexibilně spouštět různé služby a funkce (dynamické přidělování zdrojů jednotlivým aplikacím)
- přiděluje jednotlivé zdroje jednotlivým aplikacím v rámci Hadoop
- v rámci jednoho clusteru může běžet více různých aplikací najednou
- algoritmy přidělování zdrojů
- capacity scheduler
- fair scheduler
- FIFO scheduler
- hlavní komponenty
- Container
- reprezentuje zdroj (CPU, memory, disk…)
- v rámci kontejneru jsou spouštěny jednotlivé úlohy
- ResourceManager (master)
- řídí alokaci zdrojů, udržuje si globální informace o dostupných zdrojích v clusteru
- komunikuje s NodeManagery
- dostává žádosti od ApplicationMastera
- NodeManager (slave)
- běží na každém slave uzlu a sleduje jeho stav + spouští jednotlivé kontejnery
- reportuje pro ResourceManager
- ApplicationMaster
- každá aplikace ho má
- žádá zdroje od ResourceManagera pro svoji aplikaci
- řídí tasky a úlohy v rámci své aplikace
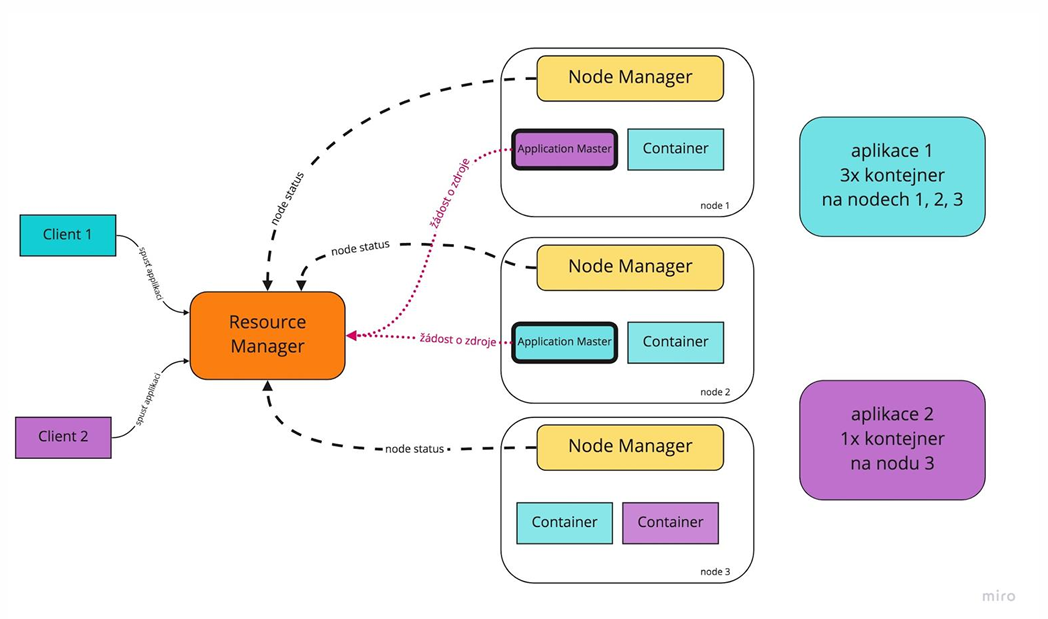
- Container
Vhodné úlohy
- dávkové zpracování dat, zpracování logů, indexace
Nevhodné úlohy
- ty vyžadující nízkou latenci či časté iterace (např. strojové učení)
Kde se používá?
- Apache Cassandra
- Apache HBase
- Apache Hive a další Apache projekty
Kdo ho používá v reálu?
- Facebook, LinkedIn, Spotify, Yahoo!
Kritika
- je to vlastně jenom distribuovaný bruteforce
- nemá databázové schéma, indexové struktury
- nemá query language
- nemá transakce, integritní omezení, pohledy apod.
- není vhodný na strojové učení, data mining, business intelligence