Teorie množin + Boolská algebra (AND, OR a NOT)
Pro vyhledávání je lepší pro každý term mít vektor documentů, ve kterých se nachází. Tedy term-by-document matrix.
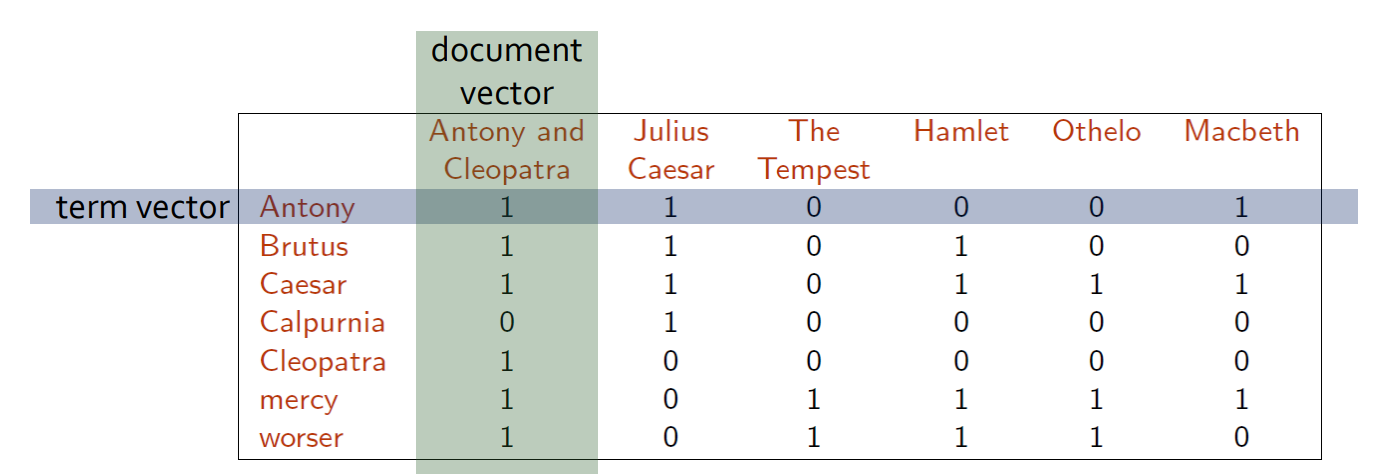
- můj dotaz: Brutus AND Caesar AND NOT Calpurnia se převede do “binárky” a nad touto binárkou se provedou příslušné operace a pak, kde mi vyjdou jedničky, takové documenty chci mít ve výsledku
Pro hodně termů a hodně documentů je taková matice hooodně řídká ⇒ invertovaný index, což je kompaktní reprezentace řídké matice.
- každý vektor převedu na invertovaný seznam, který je seřazený podle IDs documentů a vektor termů obsahuje jen ty documenty, ve který se nachází
- takový list se pak procesuje “merge sort” stylem
- je to efektivní způsob implementace, pokud
- velmi časté termy jsou v preprocessingu vyfiltrované - vznikaly by moc dlouhé seznamy
- dotaz nemá moc klíčových slov (cca 2-5 max) - faktor multiplikace
- seznamy musí být seřazené
- collection je spíše statická - vložení nového documentu by znamenalo přidat jeho ID do velikého množství všech invertovaných listů
AND = průnik, OR = sjednocení, NOT = doplněk
Pros
- velmi jednoduchý model
- efektivní implementace
- dobré pro “profesionální vyhledávače” → třeba právníky - vědí, na co se mají ptát
Cons
- uživatel musí přesně vědět, co má hledat, což většinou neví
- kvůli ANDům je to moc specifické, kvůli ORům zase moc obecné
- výsledek se mi nevrací nijak seřazený, všechny documenty jsou stejně relevantní
Rozšířený Boolovský model
-
kvůli vyřešení mínusu klasického modelu - neřazení výsledků
-
místo 0 - term není v documentu, 1 - term je v documentu tam dáváme jednotlivé váhy
- váhy jsou normované (tj. aby váha slova z velké knížky (kde se hodně opakuje) byla stejná jako z krátkého článku - kde se také opakuje)
-
díky rozšířenému modelu můžeme vyhledávat plně relevatní i částečně relevantní documenty
-
trochu kombinace s Vektorový vyhledávací model
-
každý document je vlastně vektor (dimenze m; m je velikost vocabulary)
- využívá se vážená euklidovská vzdálenost
-
výsledek je celá collection dokumentů s klesající relevantností (uživatel může nastavit, kolik relevantních výsledků chce vidět)
Pros
- stále jednoduchý pro uživatele
- uživatel může specifikovat váhu různých termů, na které se ptá
- tedy výsledek už není založen jenom na tom, zda-li se term v daném dokumentu nachází, ale i na jeho relevantnosti vůči celému documentu
- mnohem větší kvalita vrácených informací (co se týče relevantnosti)
Cons
- výpočetně náročné + starání se o seřazené výsledky