Content-based model. Známý také jako BoW (= bag of words) model, kde document je tzv. bag of terms - každý term může být v documentu vícekrát (chci znát jeho počet v daném documentu).
Dotaz je ve stejné formě jako každý document, tedy ve vektoru. A hledá se vzdálenost mezi těmito dvěmi vektory. Vektor má dimenzi m = počet termů ve vocabulary. Hodnota na i-té pozici udává důležitost (váhu) termu váhá 0 znamená, že tam daný term není.
Dotaz může být pár klíčových slov (např. psaní do Googlu) nebo celý document (např. hledání shody kvůli plagiarismu).
Zde je důležité správně zvolit váhy jednotlivých termů, to se dá dělat několika způsoby:
- document-scope statistics - více frekventované termy, vyšší váha (samozřejmě normalizované do 0..1)
- collection-scopa statistics - termy, které se opakují v hodně documentech budou mít menší váhu
Rozdělení váh termů
Populární “váhové” schéma: tf-idf
- udává, jak důležitý je term v documentu vzhledem k celé collection
- tf = term frequency (v documentu)
- idf = inverse document frequency - měří důležitost slova v celé collection - pokud se slovo objevuje v mnoha dokumentech, tak není dobrým diskriminátorem pro konkrétní document (a dokonce může jít i o stop slovo).
- počítá je jako m je celkový počet documentů v collection, n je počet dokumentů obsahující slovo
- a celková váha se pak počítá jako TF * IDF, tedy slovo, které je hodně frekventované v rámci jednoho documentu a moc se neobjevuje v dalších documentech, má vysokou tuto váhu
Podobnost vektorů
Eukleidovská vzdálenost není vhodná - pokud se nějaké documenty v sobě opakují (kopie), tak to počítá příliš velkou vzdálenost. Musí se procházet celá matice.
Podobnost se počítá podle úhlu. Vektor q je query vector. Výsledek jsou pak všechny documenty, jež mají vektory v daném thresholdu a jsou seřazené podle podobnosti ke q. Tato technika se jmenuje kosinová vzdálenost.
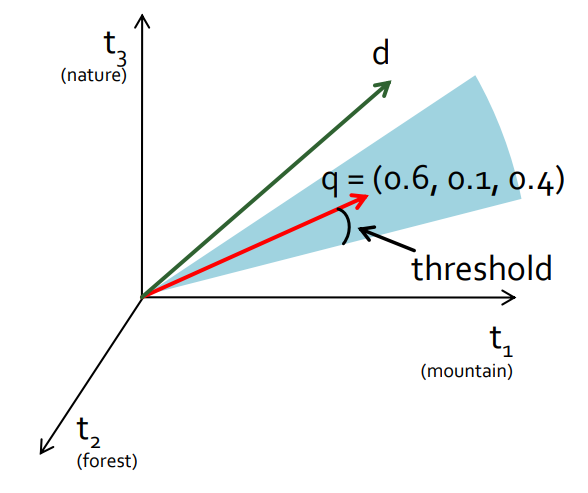
Pros
- jednoduchý a dobře definovaný přístup, geometrický model
- řazení výsledků
- efektivní implementace (pomocí invertovaného indexu)
Cons
- nemá expresní sílu Booleovského modelu
- má příliš jednoduché dotazy
- kvůli geometrizaci (váhy a vektory) nemá moc sémantických informací
- neřeší synonyma a homonyma
Jde zlepšit pomocí Latent semantic indexing (LSI)
Word2vec také využívá vektorový prostor
- stejně tak moderní metody založené na vektorových embeddizích