- open-source framework pro distribuované zpracování velkých dat in-memory (v paměti)
- umí hodně paralelizovat a optimalizovat výpočty → hodně vysoký výkon
- umí zpracovávat požadavky najednou (batch processing) a nebo v proudu (stream processing)
- umí taky machine learning, práci s grafy a SQL dotazy (je hodně univerzální)
Architektura
Komponenty:
- Driver Node (master)
- koordinuje aplikaci, vytváří DAG výpočtů (viz níže) a komunikuje s Executors
- Executor (slave) - na Worker Node
- běží na jednotlivých worker uzlech, vykonávají tasky a drží data v paměti
- Cluster Manager
- spravuje zdroje pro Spark aplikaci (např. v YARN, Kubernetes atd.)
- Driver komunikuje s Worker nodes a posílá jim tasky
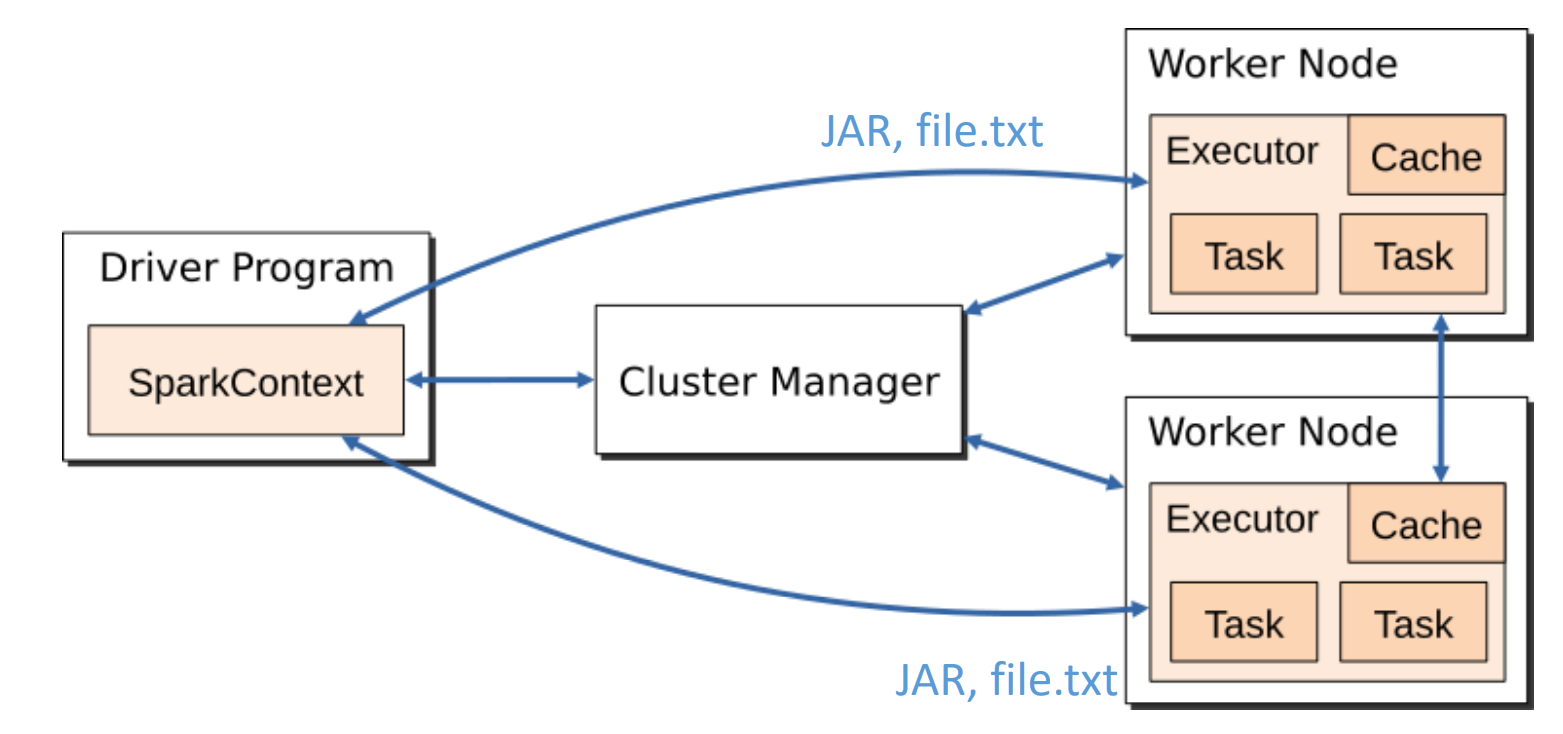 Součásti:
Součásti: - SparkContext - instance Spark aplikace, bez něj to nefunguje
- převádí aplikaci na DAG jednotlivých úloh
- Job - počítá výsledek akce, největší část výpočtu
- Stage - logická jednotka výpočtu
- Task - výpočet jedné stage nad jedním uzlem (vykonává ho Executor na Worker Node)
- např. 800 tasků na načtení 800 souborů z HDFS
- tedy Spark Application definuje jednotlivé Joby, co se musí udělat, každý Job má Stages a Task je výpočet té jedné Stage nad daty jednoho uzlu
Principy zpracování:
- RDD (Resilient Distributed Dataset)
- = základní datová struktura pro distribuované zpracování, je to vlastně dataset, který je rozdělený přes několik uzlů najednou
- RDD je
- immutable - každá transformace vytváří nové RDD
- resilient - odolné vůči selhání, chybějící části (uzly) lze znovu vypočítat
- distributed - data jsou na více uzlech
- velká výhoda oproti Hadoop s MapReduce
- pokud chci využívat nějaká data znovu a znovu pro nějaké operace, v Hadoopu se zprocesovaná data musí uložit na disk a pak znovu načíst (což trvá dlouho)
- Spark umí svoje RDD ukládat do RAM paměti a pak si je načítat mnohem rychleji
- je to tím, že jsou immutable, takže se pomocí transformací tvoříme nové a nové
- další (novější) je pak DataSet a DataFrame (koncepčně je to tabulka na strukturovaná data)
- DAG (Directed-Acyclic-Graph)
- Spark si generuje DAG, který definuje posloupnost operací nad daty (transformace a akce)
- aby se pořadí operací optimalizovalo, nebyly tam cyklické závislosti a všechny operace byly provedené ve správném pořadí
Typy operací ve Sparku
Transformace
- operace, které vytvářejí nové RDD z existujících (jsou immutable, takže pro změnu se musí vytvořit nový)
- typy
- narrow - ke zpracování stačí data z jedné partition
- není nutné data stěhovat po síti
- wide - ke zpracování potřebují data z více partitions
- vyžaduje Shuffle - je potřeba data přenést po síti (což je weak point) Akce
- narrow - ke zpracování stačí data z jedné partition
- spouštějí výpočty a vracejí výsledky
- může spustit celý DAG
Tedy nad datami se provádí transformace (až transformací) než se uvedou do požadovaného stavu a pak se nad nimi provede určitá akce, která má výsledek pro klienta nebo pro nějakou navazující akci
Lazy evalutation
- operace nad RDD se spouští až když se zavolá nějaká akce, která data potřebuje, dřív ne
- tento přístup umožňuje optimalizaci výpočtů
Moduly
- Apache Spark je hodně modulární (hodně modulů pro různé zpracování dat)
- Spark Core
- základní vrstva pro distribuci a paralelizaci dat pomocí RDD
- Spark SQL
- modul pro strukturovaná data, podporuje DataFrames a Datasets a podporuje SQL-like dotazy
- Spark Streaming
- proudové zpracování dat v téměř reálném čase
- MLlib - knihovna pro machine learning
- GraphX - pro zpracování grafových dat, např. analýza sítí