MLB 8. lecture - Text and Association rules Mining
6 min čtení
this has a lot of applications, because text is everywhere
Text mining
Structured vs. unstructured data
structured (in databases, with data types, columns, rows etc.), are easy to process, retrieve and analyze, no need to preprocess them much before classifying
unstructured data (text, audio, video etc.), meant for humans, not machines, 80 % of data out there, requires extensive preprocessing before classifying
How to preprocess text?
different names for the same thing, grammar mistakes, extensive use of punctuation, sarcasm etc.
common techniques:
text normalization = everything in lowercase
stemming = reducing words to their word stem or base form
IDF = inverse term frequency (in the whole corpus)
words with IDF = 1 occur in all documents in the corpus
words with high IDF occur in one, two documents max (very rare words)
IDF = 1 + log(total number of documents in the corpus / number of documents containing term t)
final score for term t: TF(t,D)∗IDF(t)
often the Cosine Similarity is used for determining the relevance of the search query to a corpus of documents
each document has a vector of TF-IDF scores for each term in that document
the query also has a TF-IDF vector
the cosine similarity of those vectors is calculated
Named entity recognition (NER)
we want to identify the named entities (locations, countries, product names, political groups, dates etc) in the text
these terms are often very meaningful
methods:
expertly maintained entity dictionaries
NER models trained for this purpose (on a labeled training dataset)
open-source library for Python: SpaCy
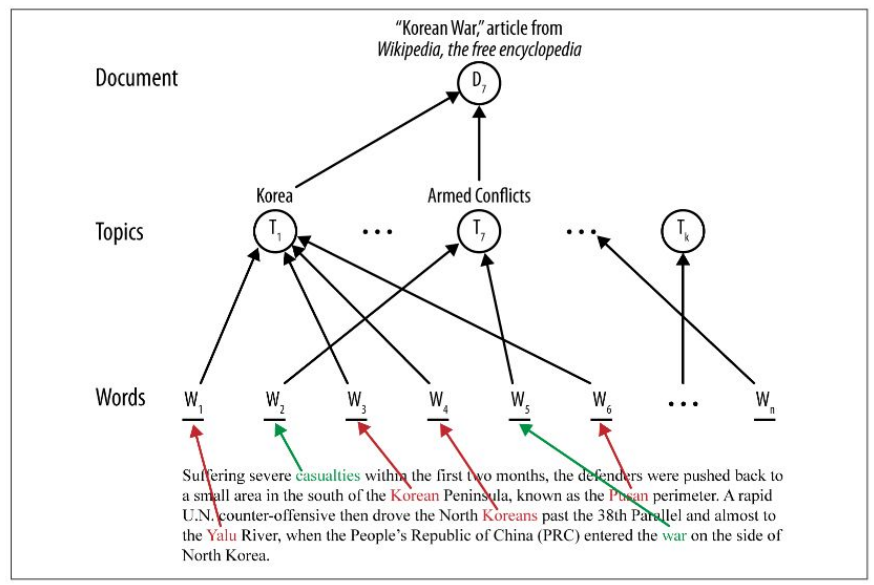
Topic models
they form another layer next to documents and terms and they define topics for the whole corpus and then words/terms could be related to some topics, which also enhances the information quality over the corpus and documents
usually the corpus deals with a limited number of topics
Word embeddings
they model words as dense vector representations in a low-dimensional space
the idea: words with similar meaning will have a similar representation
therefore, they will be closer to each other
methods:
Word2Vec, GloVe etc.
existing pre-trained word embedding models: BERT, fasttext, GloVe
beware of the biases there
it often connects e.g. men to programmers and women to homemakers
Association rule mining
examples: what products are purchased together, plagiarism detection, related concepts identification etc.
Terminology
itemset = a set of items
which often occur together in individual transactions (also called frequent itemsets)
could be also items, which are not together in any transaction
or items, which form some kind of rule together
Association rule
it indicates an affinity between the antecedent itemset and consequent itemset
affinity = how strongly do these two items occur together
it consists of two itemsets:
antecedent = left-hand side (LHS)
consequent = right-hand side (RHS)
the translation is like this: IF antecendent happens → then the consequent happens (usually) as well
metrics:
support = “how often do the antecedent and consequent appear together?”
if there are 100 transactions and {milk, butter, apples} are all in 20 transactions, the support is 20/100 = 0.2
confidence = “when A occurs, how often does C occur as well?”
if there are 100 transactions, A (antecedent) is in 20 of them and C (consequent) is in 10 out of those 20