in this technique, the performance of weak learners (often really dumb decision trees with depth of 1, slightly better than random guessing) by training many weak learners sequentially
and each successive model is trained to fix the mistakes of the previous model (to minimize the error)
in bagging, the weak models are trained independently, in boosting, each model depends on the previous ones
AdaBoost
= Adaptive Boosting
it works by reweighting samples after each iteration
at the beginning, all training samples have equal weight and first weak learner is trained (usually a decision stump, a tree with one split)
then the error rate for this stump is calculated + it’s weight is calculated based on it’s accuracy (better accuracy = higher weight, it’s important for the final prediction)
the weights for misclassified samples is increased, weights of correctly classified samples are decreased
to show the model, which samples are more important to get right (the model is punished more for getting them wrong)
the next learner then focuses on the harder samples
the final prediction is a weighted vote of all learners (base estimators)
advantages: high focus on difficult cases
disadvantages: it is sensitive to outliers and noise (it keeps focusing on outliers, which could be just mislabeled data)
Gradient Boosting
examples: XGBoost, CatBoost or LightGBM
the final prediction is made from adding results of the weak learners together
the weak learners (base estimators) are learned sequentially
instead of reweighting samples, each new model is trained to predict the residual errors of the previous models (the ensemble in progress)
first guess is just a number (usually a mean of the values etc.)
the residual errors of the first guess are calculated and the first weak learner is trying to predict these residual errors (to predict, how much to add/subtract from the initial guess to get closer to the real label/target)
then the residual errors of the first guess + the predicted residual error from the first weak learner are calculated
then a second, successive weak learner is trained to predict the residual errors of the sum (we can do supervised training, because, we have previously calculated the real residual errors)
the final prediction is then the sum of the first guess and the sum of the “nudges” of respective weak learners
the previous models are gradually added together to create an ensemble
the residual errors form a gradient (negative, we want to decrease, minimize the loss)
gradient values are numeric, so in reality, the regression problem is being solved, even for classification
when adding the models together, each is scaled by a shrinkage factor (which is a hyperparameter) which controls how much influence this tree has on the overall model
the shrinkage factor is the same for each model, the values are often 0.1 or 0.01 and this is mainly for slowing the model down, we don’t want to “correct” the initial guess by 5 big trees, but rather by 500 small “nudges”
beware of easy overfitting, but othewise this is one of the best ML models out there for tabular data
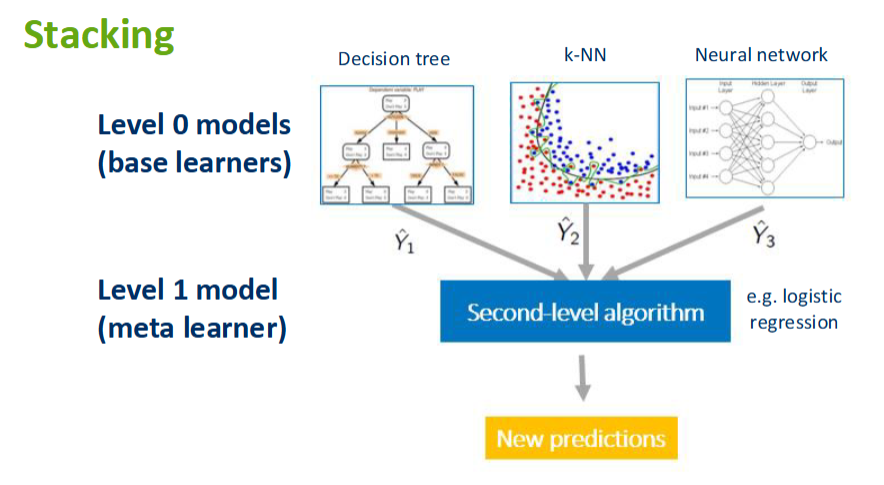
Stacking
in this technique, we stack different learning algorithms on top of each other
those algorithms are strong learners (logistric regression, decision trees, neural nets, SVM, random forest, naive bayes etc.) trained on whole dataset
the idea is that each model captures different patterns in the data and when combined in the meta-model, it can predict even better (be more generalized)
the meta-model (level 1 model/learner) treats all predictions from different models (level 0 models/learners) as data instances (as meta-features) and is learning, which features contribute the best to the target label
the meta-model could be for example logistic regression (not learning on training data, but on the predictions of the already-trained base estimators)