a simple model or strategy to which we can compare other models or approaches
it should tell us to invest more (or not)
the usage of concrete baseline differs by the desired usage
baselines:
random classifier = assigns a random label to every sample
comparing to this classifier we measure how much did the model learn from the data
if the model has the same or similar accuracy, the model learned nothing (it acts as a random classifier)
majority classifier = assigns only one label to every sample (the one that is majority, often it is 0)
so if the majority of target label is 0, it will without exception assign 0 to all predictions
if majority classifier has accuracy 97 % (because the 97 % of all samples are negative), having model accuracy 97.1 % is not that great
single data source classifier = uses only one data source
we can measure if adding a new data source improves the model or not
simple model (logistic regression, decision tree)
if we should invest in an advanced modelling techniques or not
Visualizing the performance
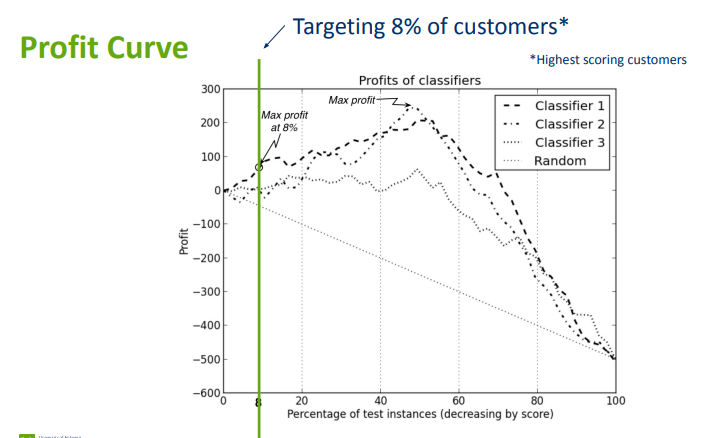
Profit curve
we score the customers using our classifier (e.g. the higher score means more probability that the customer will buy/convert)
and the goal is to calculate the profit of targeting top X% of customers
it’s the revenue if the customer buys - costs for the targeting (e.g. marketing)
if we target 0 % of customers, the revenue will be zero (logically)
if we target 100 %, we will have negative revenue (the cost of targeting is higher than the cost of buys from the best customers) + we don’t need to model
the added value of the model is the area between random classifier and the profit curve