- modularity is one of the most fundamental concepts in engineering - applicable to all man-made artefacts (cars, buildings, software systems etc.)
- an artefact = any man-made product composed of parts
- why is modularity important?
- hierarchical structure allows for better control and separated development
- complexity reduction - each module can be understood, developed and tested independently (even by different engineering teams)
- reuse of components across different artefacts
- evolvability/flexibility - modules can be changed, replaced or extended without reworking the whole artefact
- why is it hard?
- the implementation of a modular structure is not straightforward
- changes, extensions to modules or their non-identical replacement can ripple/propagate through the whole artefact and make serious impacts
- deep issues of evolvability and scalability emerge and they increase with the number of variants and modules
- modularity is not just something that lives in the design - it must be maintained across all phases:
- design - defining modules and their interfaces
- manufacturing/implementation - the production process must be modular and hierarchical as well
- deployment - there should be integration units for aggregation (putting modules together)
- evolution - the modular structure must survive changes over time
- a software program is also an artefact, it consists of the source code artefact and execution code artefact
- it also contains a number of hierarchically structured modules
Variation gain
- the key combinatorial insight behind modularity:
- module variants grow additively - if we have m modules and each has v variants, the total number of module variants is m × v
- product/artefact variants grow multiplicatively - the number of possible product configurations is v^m (exponential)
- this means the variation gain (the ratio of product variants to module variants) can be exponential
- for a relatively small number of modules and variants, we get a huge number of potential artefact configurations
- but this exponential power has consequences:
- the manufacturing/assembly process has to be modular and hierarchical as well (to handle all the configurations)
- there should be integration units for aggregation (putting modules together)
- and if coupling is not managed, the ripple effects can also grow exponentially (exponential ripple costs)
GRASP - Vysoká soudržnost - High cohesion
- a design principle: separating functions into high-cohesive modules (units of work)
- each module should contain exactly one responsibility or “change driver”
- to avoid duplication (by separating the functionality to a single place)
- then changes won’t be done at many places, but just one place
- to be able to easily create more variants and enable support for them
- to avoid duplication (by separating the functionality to a single place)
- modules are single units of work that have their “interface” and are high-cohesive (all related functionality is grouped together)
- modules can have variants - we don’t have to copy the whole artefact if we add another variant
- we get exponential variation gains
- note: in NST, this idea is formalized as the principle of “Separation of concerns” - each action entity should contain only a single task or change driver
GRASP - Nízká provázanost - Low coupling
- a design principle: carefully managing the connections between modules
- the goal is to:
- avoid the propagation of changes to the entire artefact (danger of exponential ripple costs)
- avoid negative impact to the integration at deploy time
- it is not about not connecting/coupling at all, but carefully thinking about the nature of the connection (whether the ripple effects pass through or not)
- only meaningful connections should exist
- encapsulation is the key mechanism:
- we want to encapsulate all modules, so the changes within them do not ripple and propagate through the whole artefact
- this works for the connections as well - if the connection is encapsulated, the changes won’t ripple through
Beware of unleashing the exponential variation gains (through high cohesion) without mastering the coupling as well - otherwise you also get exponential ripple costs.
Cross-cutting concerns
- concerns/functionalities that cut through the main hierarchical structure in another dimension
- they don’t belong to any single module but affect many or all modules
- examples: heating in a building, energy supply, security, logging in software, data persistence etc.
- they can create ripple effects across the main structure if not handled properly
- this section discusses integration in general (for any artefact) - software-specific handling of cross-cutting concerns is discussed later
How to integrate cross-cutting concerns
- there are two main dimensions to consider:
- embedded vs relay - is the concern implemented inside each module, or centralized with modules delegating to it?
- dedicated vs standardized - is the implementation specific to one artefact, or reusable across artefacts?
- the integration levels form a progression from least to most desirable:
- 1A - embedded dedicated integration
- the concern is embedded and dedicated to each module - it’s special for each structure
- e.g. a special fireplace for every room in a house
- this is the least desirable - every change to the concern requires big changes in every module of the main structure
- not encapsulated
- the concern is embedded and dedicated to each module - it’s special for each structure
- 1B - embedded standardized integration
- the concern is embedded in each module, but it’s standardized - the same solution can be used across different structures
- e.g. standardized heaters in every room in a house
- the same heater could be placed in other houses
- it can be easily replaced or removed without big changes for the modules
- e.g. standardized heaters in every room in a house
- standardized modules are well encapsulated
- the concern is embedded in each module, but it’s standardized - the same solution can be used across different structures
- 2A - relay to dedicated framework
- there is one single centralized module for the functionality and all modules relay to it
- e.g. a centralized heating system/boiler - there does not have to be a fireplace in each room
- removes duplication, but the framework is still specific to one structure
- there is one single centralized module for the functionality and all modules relay to it
- 2B - relay to standardized framework
- the same as 2A, but the framework is standardized and shared across multiple structures
- e.g. the energy system (power plants, transmission, distribution, consumption) - one system for all houses
- e.g. the internet - a centralized and standardized framework that enables Spotify, Netflix, Amazon etc. without establishing a new network for each service
- no duplication, standardized, reusable
- the same as 2A, but the framework is standardized and shared across multiple structures
- 2C - relay to framework gateway
- a gateway exists that provides dedicated connections for each structure and communicates with the standardized framework on behalf of the structures
- e.g. an energy gateway for a house that talks to the grid - thanks to the gateway, it’s easy to switch energy providers (the house is not connected directly)
- the gateway adds an extra layer of encapsulation between the structure and the framework
- a gateway exists that provides dedicated connections for each structure and communicates with the standardized framework on behalf of the structures
- 1A - embedded dedicated integration
Guidelines for integrating cross-cutting concerns to the main structure
- guideline 1: encapsulation
- shield the main hierarchical structure from ripple effects caused by changes in the external concern implementation
- 1A is not encapsulated (changes in the concern ripple into every module)
- 1B and above are encapsulated - that’s what we want
- guideline 2: interconnection
- remove duplications - changes should not have to be made in several places
- achieved through central implementations (relay approaches 2A, 2B, 2C)
- the relays themselves must also be encapsulated, so a change of the concern does not ripple into the main structure
- e.g. we can exchange the central heating system without changing the pipes and radiators
- guideline 3: downpropagation
- extending the main hierarchical structure has impacts on cross-cutting concerns
- e.g. adding one more room also requires connecting it to the central heating, electricity, water etc.
- if integration with concerns happens at a high/coarse level, extending the main structure becomes complex and causes ripple effects (because all concerns need to be connected/integrated for each new module)
- the solution: push the integration as deep as possible into the finest-grained building blocks
- build the modules from “pre-integrated” parts - like bricks with built-in pipes for drinking water, heating water, electricity, internet etc.
- when you compose a new module from these blocks, the cross-cutting concerns come pre-integrated
- how to limit the impacts in practice:
- have a separate domain/dimension for each cross-cutting concern and handle it at the fine-grain level
- each module has different layers through which it connects to each concern dimension - so the concerns don’t interfere with each other
- extending the main hierarchical structure has impacts on cross-cutting concerns
Representation framework - Integration Design Matrix
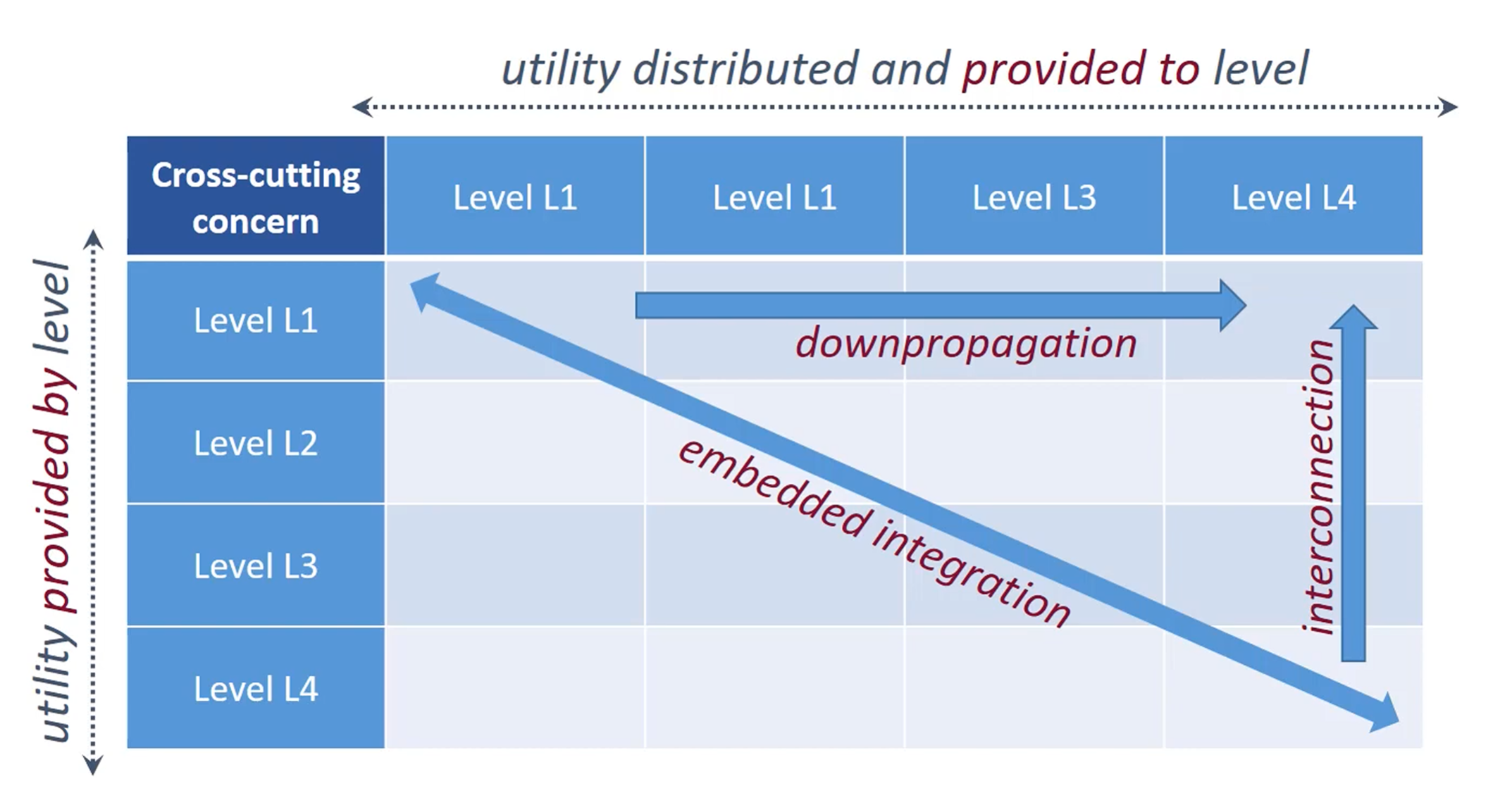
- a matrix representation that facilitates the design of a hierarchical architecture with multiple cross-cutting concerns
- both axes represent the hierarchical levels of the artefact (L1 = highest/coarsest, L4 = lowest/finest-grained):
- rows (left axis) = “utility provided by level” - which level supplies/produces the functionality
- columns (top axis) = “utility distributed and provided to level” - which level consumes/receives the functionality
- a cell at row Li, column Lj means “level Li provides utility to level Lj”
- the diagonal represents embedded integration - a level providing utility to itself (the provider and consumer are at the same level)
- the lower-right area of the matrix represents “production” - distributed fine-grained levels collecting and providing resources upward to higher levels
- encapsulation is discussed at the level of each cell - is the integration at this point encapsulated so that external changes won’t affect it?
How the three guidelines map onto the matrix
- downpropagation (horizontal arrow, top row, going right)
- push the integration of cross-cutting concerns from high levels toward lower, finer-grained levels
- instead of integrating at L1, push it down so it’s handled at L3, L4 etc.
- embedded integration (diagonal arrow, top-left to bottom-right)
- concerns that are embedded within each level - the providing level and consuming level are the same (they are in each module)
- relates to the 1A/1B integration approaches
- interconnection (vertical arrow, right side, going up)
- fine-grained levels (e.g. L4) provide utility upward to higher levels through centralized frameworks (like the relay approach)
- relates to the 2A/2B/2C relay approaches
Normalized Systems Theory - core
- the central question: how do modular systems change and behave under change?
- NST is a theory about how to build modular software that is able to evolve and adapt to new settings/environments in a sustainable way
- while the theory originates from software, its principles are applicable to other domains with modular man-made artefacts
- the problem: when we change software, its complexity increases (unless we do refactoring) - over time it gets more and more complex and that is not sustainable
- this is not just a practical observation, it can be explained theoretically
Foundations from other domains
- stability from Systems Theory
- a system is dynamically stable when a bounded input produces a bounded output
- positive feedback causes instability - one input triggers further changes, which trigger more changes etc., resulting in unbounded output
- in software: adding features, fixing errors, changing code/architecture can create ripple effects, and ripple effects create more ripple effects - resulting in unbounded output (positive feedback)
- dynamic instabilities = combinatorial effects
- one small change in software results in many changes in different parts of the software, potentially changing the whole application
- there is coupling, there are ripple effects
- entropy from Thermodynamics
- systems naturally tend toward disorder - software entropy increases with each change unless actively managed
The 4 NS principles
- it can be proven that any violation of these principles leads to combinatorial effects
- following the principles is a necessary (but not always sufficient) condition for building software without combinatorial effects
- the four principles correspond to the fundamental types of coupling that cause combinatorial effects
- the goal is to build software with zero or the least amount of combinatorial effects
- the challenge: every developer has to avoid violating the principles at every point during the entire lifetime of the software (could be 20+ years of development)
1. Separation of concerns
- an action entity can only contain a single task or change driver
- a change driver = anything that could cause a change in the system (new requirement, bug fix, technology update, data structure change etc.)
- each change driver should be isolated in its own module
- we have to identify change drivers - modules/components that will be changing, or could be changed - and isolate them
- a change should only affect one place, not many
- also requires good API design so that concerns can communicate with each other
- encapsulation of functions, classes, actions
- encapsulate external modules (e.g. logging)
- new change drivers have to be implemented in new modules and other modules point to them or use them via API
2. Data version transparency
- some pieces of software are dependent on data and data structures
- creating, passing, consuming pieces of data etc.
- when the data structure changes, it causes positive feedback (ripple effects) on related/dependent modules
- the solution - data version transparency / data encapsulation:
- encapsulate data in classes and structures
- do not do data coupling (passing individual fields as separate parameters)
- prefer stamp coupling - passing whole data structures even though the function/class needs only a few fields
- e.g. if a function takes
(name, address, phone)as separate parameters and we addemailto the data entity, the function signature must change (ripple effect) - but if the function takes the whole
Customerobject, addingemaildoesn’t change the signature - the function simply doesn’t use that field - if something inside the data structure changes, it will not change the function’s interface - no ripple effects
- e.g. if a function takes
3. Action version transparency
- when a new version of a task/action is introduced (new implementation, bug fix, new variant of a function), existing callers should not need to change
- in traditional software development I would change the implementation (potentially causing combinatorial effects)
- the solution:
- encapsulate actions are behind stable interfaces
- use versioned implementations and delegation patterns
- a new version can be added without modifying existing code that calls the action
- there is a delegator element inside the element, which decides (depending on the context, parameters, specific logic…) which concrete implementation to use
- all versions/implementations of the action are in the codebase, so no legacy code is broken
- the caller interacts with a stable interface - it does not know or care which version/implementation of the action is executing behind it
- without this, adding or updating a single action can ripple to all modules that depend on it
4. Separation of states
- all states that a system could be in should be transparently described and saved
- the system should be designed so that adding a new state does not require changing the state-handling mechanism itself
- stateful workflow is preferred:
- something produces a state, something else picks it up and does something else - they are decoupled and waiting for each other
- isolate atomic actions and expose transaction states
- e.g. a new error returning from a function should not require “adding a new error state/handling code everywhere” - the structure returning from the function should be generic enough to contain any new states
- keep the change within a single object and do not let ripple effects impact anything else
High cohesion and Low coupling (revisited)
- these principles must also be adhered to alongside the four NS principles
- low coupling is also about the nature of the coupling
- e.g. a logger used by tens of other modules is okay - it is called reuse and it makes sense not to duplicate it to lower coupling
- but the logger should do everything log-related and should not change its interface (that would cause ripple effects)
Cross-cutting concerns in software
- in general engineering, we discussed how cross-cutting concerns cut through the main hierarchical structure and how to integrate them (levels 1A-2C, three guidelines)
- in software, the same problem exists - these concerns are well known and many developers/businesses have to cope with them:
- access control, persistency/data handling, transactions, remote access, logging, error handling, UI rendering, concurrency, monitoring etc.
- there are open-source/third-party libraries and frameworks that handle these (we want to use them to not reinvent the wheel)
- but we want to separate and encapsulate their integration points in our code, so if external libraries change, the ripple effects will not cut through the main functional structure
The element - NST’s building block
- the idea: transform a single class into a set of multiple classes tied together - this set is called an “element”
- structure of an element:
- a core class in the center - contains the business logic and is one of the 5 types of elements (data, task, flow, connector, trigger)
- surrounding classes - each handles one cross-cutting concern by delegating to a third-party library/framework
- e.g. one class for persistence, one for access control, one for logging, one for error handling etc.
- all of this is encapsulated together as one element
- the element exposes a stable, technology-agnostic interface to the outside
- how this prevents combinatorial effects:
- if something changes (e.g. a third-party library is updated), there may be some impacts within the element (specifically in the surrounding class that interfaces with that library), but the changes are contained/bounded
- the core class is not affected
- other elements are not affected
- the elements are like building blocks that “absorb” ripple changes
- this structure relates to the integration levels discussed earlier:
- the surrounding classes implement embedded standardized integration (1B) - the same structure is used in every element
- the delegation to external frameworks implements relay to standardized framework (2B/2C)
- each surrounding class is a standardized relay point
- because the interface is stable and technology-agnostic, the underlying technology can be swapped (different database, different logging framework) without affecting anything outside the element
- visual representation:
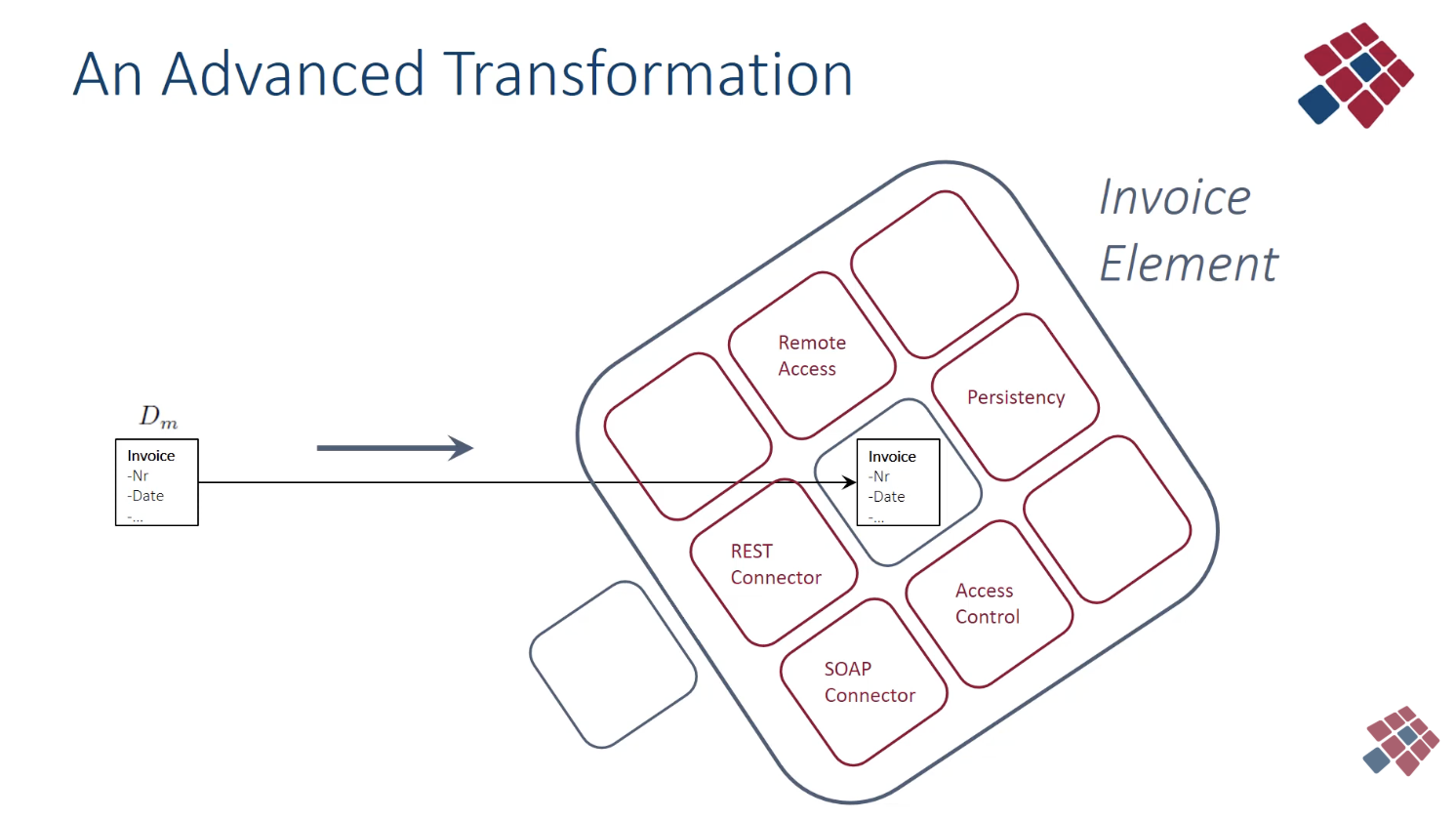
5 types of elements
- NS defines 5 element types, corresponding to the fundamental categories of software functionality:
- data elements - represent data variables and structures
- e.g. Invoice (number, order…), Order (date, amount…), Customer (name, address…)
- each data entity in the system becomes a data element with its surrounding concern-handling classes
- task elements - contain instructions and functions (the actual operations)
- e.g. CreateInvoice, ProcessOrder, CalculateDiscount
- each task/action in the system becomes a task element
- flow elements - orchestrate and control the flow between tasks
- define the order in which tasks are executed, branching, loops etc.
- connector elements - handle I/O, communication with external systems
- input/output commands, API calls, file operations etc.
- trigger elements - handle periodic or event-based control
- timers, scheduled jobs, event listeners etc.
- data elements - represent data variables and structures
Why this leads to code repetition (and code generation)
- every element, regardless of its type, needs the same set of surrounding concern-handling classes
- if there are 50 data entities, each one needs its own persistence handler, access control handler, error handler etc.
- the structure is recurring - only the core business logic in the center differs
- writing all this by hand would be enormous and error-prone
- this is exactly what makes code generation viable - the recurring structure can be generated automatically
Generating software - recurring structures and expanders
- the goal of NST: build software with extremely fine-grained modules (elements), which compose into bigger modules, which compose into even bigger modules
- writing all this code by hand is not feasible - the recurring structure of elements means we need an “assembly line” to systematically generate sustainable fine-grained code without combinatorial effects
- terminology:
- expanders = code generators/templates that produce the skeleton (the recurring structure of elements)
- mirrors/models = abstract representations of business entities and processes (e.g. “Invoice has number, date, amount”)
- craftings = all custom code added by programmers
- insertions = custom code injected into generated classes
- extensions = entirely new classes written by the programmer
- utilities = third-party frameworks/libraries that handle cross-cutting concerns
How code generation works
- the generators produce a skeleton - roughly 90% of the code - based on the models
- for every model (e.g. every data entity, every task, every flow) the expander instantiates a template and produces a complete element with all surrounding concern-handling classes
- the flow: model → expander → element (generated code) → craftings added
- the skeleton is not production-ready yet - a programmer must add custom code (craftings):
- insertions - custom code into generated classes (e.g. specific validation logic)
- extensions - entirely new classes for business-specific functionality
- the programmer could introduce combinatorial effects here (due to design mistakes, time pressure, budget constraints etc.) - this is the weak point and must be carefully managed
- the generators encode architectural decisions based on NST principles
- they also incorporate best practices from mainstream IT (DevOps, microservices, design patterns, frameworks etc.)
- these decisions are made once in the generator and consistently applied everywhere - rather than relying on every programmer to make the right decision every time
Recurring structures as variations
- all data elements share the same structure (same set of surrounding classes, same patterns)
- all task elements share the same structure, all flow elements share the same structure etc.
- the structures recur - only the core business logic differs
- to limit complexity and guarantee consistency across the whole codebase
- any improvement to the recurring structure (the template/expander) can be applied to all instances at once through regeneration
- those recurring structures may need to vary over time (new insights, discovered flaws, technology changes etc.)
- the longer we wait with the update, the more outdated it becomes and the more combinatorial effects accumulate
- this is why automatic regeneration/rejuvenation is needed
Regeneration/rejuvenation
- the idea: do not add features to the finished code - instead regenerate the whole application from scratch with:
- the updated models (new business entities, new processes)
- new versions of the expanders/templates (improved element structures)
- new versions of all utilities/libraries (new database versions, security library versions etc.)
- the regeneration process:
- 1 - harvest custom code (craftings) from the current codebase
- 2 - update whatever needs updating (models, expanders, utilities)
- 3 - regenerate the entire skeleton from scratch
- 4 - reinject the harvested craftings into the new skeleton
- 5 - test that everything works together (CI/CD)
- the key point: we don’t patch old code - we regenerate from scratch with the latest everything
- the generators themselves are also evolving, but they cannot introduce anything that causes combinatorial effects
Benefits of this approach
- no legacy code - every regeneration brings the entire codebase up to date, the application cannot get “old”
- lower maintenance costs over time
- technology-independent - the skeleton is technology-agnostic, swapping utilities doesn’t require rewriting business logic
- vendor-independent - the skeleton is vendor-neutral, there may be need to change/rewrite some of the remaining 10% of craftings (but that is manageable)
Variability dimensions
- there are four independent dimensions of variability:
- mirrors/models - what business entities and processes exist
- skeletons/expanders - how elements are structured (the recurring patterns/templates)
- utilities - which third-party frameworks handle the cross-cutting concerns
- craftings - what custom business logic is added
- because these dimensions are independent and encapsulated, they can be combined freely
- different databases with different business logic with different views etc.
- the number of versions to maintain is additive (m + s + u + c)
- but the number of possible combinations is multiplicative
- this is the Variation gain from the modularity section, now applied to the software architecture itself
- how it works in practice:
- for every mirror (an actual data/task/flow entity) an element is instantiated from a skeleton
- into the skeleton, frameworks/utilities for handling cross-cutting concerns are connected
- then craftings/custom code is added/injected
- if separated and encapsulated well, each dimension can evolve independently
Evolution scenarios
- the key property of the NST architecture: in all scenarios, the number of changes is bounded and proportional to the change itself - not proportional to the size of the system
- in traditional software, a small change can ripple through the entire codebase
- in NST, changes are absorbed locally within the relevant elements/dimensions and don’t propagate
- during one regeneration cycle, multiple dimensions can be updated simultaneously - the changes in each dimension remain independent
Mirrors/models evolution
- scenario: we change a model - e.g. adding a new data attribute to an entity, adding a new task, adding a new flow
- what happens:
- a new version of the model is created
- a new element is instantiated from the skeleton (or existing element is regenerated)
- changes may propagate within the element - e.g. some surrounding concern-handling classes get new versions (the persistence class may need to store the new attribute)
- but not all surrounding classes will be affected - e.g. the access control class doesn’t care about a new data attribute
- the important thing: the number of ripple changes is limited within the element and does not propagate to other elements
- the custom code (craftings) will not be affected, as long as it uses the standard API published by the element
- adding a new task implementation:
- we don’t modify an existing task element - instead we create a new task element (a new version/variant)
- the flow is configured to delegate to the appropriate version (delegation pattern)
- the old version remains unchanged, the new one is added alongside it
- this is action version transparency in practice
Utilities evolution
- scenario: a third-party framework/library is updated or replaced (new database version, new logging framework, new security library etc.)
- two cases:
- if only a few elements use the utility directly → change just those specific surrounding classes
- there is only a limited number of classes directly interfacing with the older framework
- if many elements use the utility through the same template pattern → change the template and regenerate all elements at once
- this is the more powerful and typical NST approach
- we change the template class dealing with this framework and then regenerate/rejuvenate the whole system
- the code expanders (generators) handle this automatically
- if only a few elements use the utility directly → change just those specific surrounding classes
- the assumption: custom code does not make direct calls to utilities, only via the standardized API of the element
- if this assumption holds, craftings are not affected by utility changes
Skeleton evolution
- scenario: we need to handle a new cross-cutting concern that wasn’t in the original design (e.g. audit logging, monitoring, a new security layer)
- what happens:
- we add a new surrounding class to the skeleton/template for the relevant element types
- we regenerate, and every element in the system gets the new concern-handling class automatically
- this is stable because the new class is added alongside existing ones - existing surrounding classes and the core class are not modified
- without NST, adding a new cross-cutting concern to an existing system would require touching every module manually - a textbook combinatorial effect
- we can also modify existing surrounding classes in the skeleton if needed (e.g. improving the persistence pattern)
- the change is made once in the template and propagated to all instances through regeneration
Craftings evolution
- scenario: custom code needs to be updated (new business logic, changed requirements, bug fixes in custom code)
- craftings must be tested in the CI/CD environment to verify that they:
- do not directly call utilities (only via standardized API)
- do not bypass the encapsulation of the element
- handle all connections/integrations correctly after the change
- traceability is important:
- each piece of custom code should be traceable to a specific business requirement or feature
- we need to keep track of the features required by the company/customers and match them with the corresponding custom code snippets
- this matters because during regeneration, we need to know which craftings are still needed, which are obsolete, and which need modification
- the risk: craftings are the one place where programmers can introduce combinatorial effects
- the better the skeleton is, the less custom code we need
- we can iteratively update the skeleton, so it would incorporate features/functions/actions from the craftings and then deleting those craftings and let code generators handle it according to NST principles
- the less custom code, the fewer opportunities for introducing combinatorial effects
Automatic programming
- automatic programming = the act of automatically generating source code from a model or template
- the goal is to improve productivity, eliminate errors, and keep maintenance costs low
- using “prefabricated” templates with parameters is faster than inventing everything again and again
- this idea also exists under other names:
- model-driven architecture/engineering/development
- low-code platforms
- in all cases, models represent domain knowledge and structure of requirements, and generators translate them into code
- the key challenges of automatic programming:
- regeneration with support for custom code (craftings)
- having custom code is inevitable - the generator cannot cover all business-specific logic
- the harvest → regenerate → reinject cycle must work reliably (discussed in the previous section)
- two-sided programming interfaces
- meta-circularity
- regeneration with support for custom code (craftings)
Two-sided programming interfaces
- the code generation system needs two independent interfaces:
- the model side - for adding, modifying, and extending domain models
- “what am I modeling?” - business entities, processes, flows, data structures
- the expander side - for adding, modifying, and extending code generators/templates
- “how do I generate code?” - element structures, concern-handling patterns, technology mappings
- the model side - for adding, modifying, and extending domain models
- these two sides are independent:
- you can change what you’re modeling without changing how code is generated
- you can change how code is generated without changing the models
- this separation is itself an application of the NST principles - the two sides are separate concerns with separate change drivers
Meta-circularity
- this is one of the most powerful concepts in NST
- the basic idea: better parts of the system create a better system, which can produce better parts, which again make a better system
- this is a positive feedback loop - but a good/controlled one (unlike the destructive positive feedback of combinatorial effects)
- in practice, this means: the code generation system generates itself
Meta-models - a practical explanation
- a model describes the business domain:
- e.g. “Invoice has number, date, amount”
- a meta-model describes the structure of models themselves:
- e.g. “a data entity can have attributes, and attributes have a name, a type, and constraints”
- the meta-model defines what models can look like - it is the model of models
- the key circularity: the meta-model is stored as data entities, which means the meta-model is itself described using the same structure it defines
- we can include a set of data entities in our model to represent the meta-model
- with these meta-models, we can generate a meta-application
The architecture (the Expander MetaCircle)
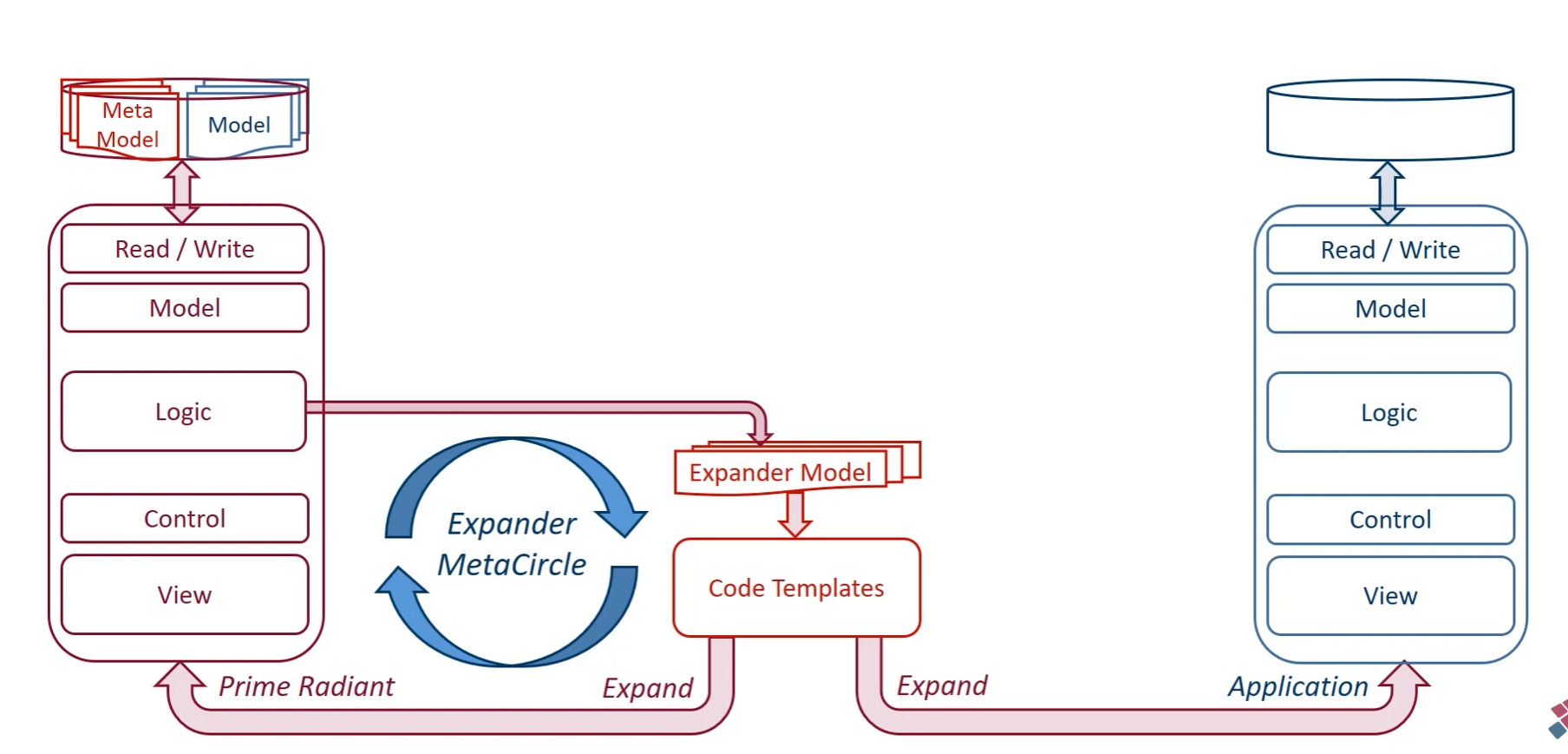
- right side (the Application) - the actual business software
- a layered application (Read/Write, Model, Logic, Control, View) with a database
- this is what the business actually uses - the end product
- generated by the Expander MetaCircle from the business models and code templates
- center (the Expander MetaCircle) - the code generation engine
- takes the Expander Model (which describes how expanders/generators work) and Code Templates (the actual templates for generating code)
- can generate in both directions - rightward to generate the normal Application, and leftward to regenerate the meta-application (Prime Radiant) itself
- left side (the Prime Radiant) - the meta-application
- a full application for managing models, meta-models, and expanders
- also a layered application (Read/Write, Model, Logic, Control, View) - structurally identical to the applications it helps generate
- at the top: the Meta Model and Model databases
- this is where architects and developers define domain models, manage expanders/templates, and trigger code generation
- the critical insight: the Prime Radiant is itself generated by the same Expander MetaCircle it manages
- improvements to the expanders improve the Prime Radiant
- a better Prime Radiant makes it easier to create better expanders
- better expanders produce better applications (and a better Prime Radiant)
Resonance
- this controlled positive feedback phenomenon is called resonance in NST
- improvements in one part of the meta-circular system amplify improvements in other parts
- because the whole system is built on NST principles (encapsulation, separation of concerns), the feedback leads to improvement rather than instability
- the combinatorial effects are prevented by the same principles that govern the generated applications
NSX Project
- NSX (Normalized Systems eXpander) is the concrete implementation/research project at UAntwerp that puts NST into practice
- the Prime Radiant is part of NSX - it is the tool used to manage models and generate NST-compliant applications
- NSX serves as both a proof of concept for the theory and a practical platform for building enterprise software following NST principles